Sentry For Data: Error Monitoring with PySpark
Sentry For Data: Error Monitoring with PySpark


Data pipelines and analytics tooling have become essential parts of modern businesses, so why are error monitoring and observability tooling for data tools still 10 years behind modern application development? Logs are just not good enough to make sure you can quickly and efficiently debug your errors.
After experiencing struggles with combing through lengthy and confusing logs to debug our data pipelines at Sentry, we built out monitoring solutions using Sentry for popular data tools, Apache Beam and Apache Airflow. Now, we've built a new integration for PySpark, the Python API for Apache Spark.

It’s just logs all the way down
With this integration, errors that were just lines in a log file become full context events in Sentry that can be tracked, assigned and grouped. Each error contains metadata and breadcrumbs that help you isolate the current state of your Spark Job, so you can dive right down into the source of the error.
The PySpark integration works out of the box for SparkSQL, Spark Streaming, and Spark Core, and also works on any execution environment (Standalone, Hadoop YARN, Apache Mesos and more!). The integration can be set up to monitor both master and worker clusters with just a few lines of code. Optionally, you can customize it more based on the needs of your setup.
Installing Sentry on Spark Clusters
To get as much visibility as possible into your Spark Jobs, it's important to instrument both Spark's driver and workers.
To get started, install the Sentry Python SDK on your Spark execution environment. Make sure you install sentry-sdk>=0.13.0. If you are running Spark on multiple clusters, it makes sense to run an initialization script to install Sentry.
pip install sentry_sdkDriver
The driver integration requires Spark 2 and above. To get the driver integration working, initialize Sentry before you create your SparkContext/SparkSession with the SparkIntegration.
import sentry_sdk
from sentry_sdk.integrations.spark import SparkIntegration
if __name__ == "__main__":
sentry_sdk.init("___PUBLIC_DSN___", integrations=[SparkIntegration()])
spark = SparkSession\
.builder\
.appName("ExampleApp")\
.getOrCreate()
...Now all your Spark errors should start showing up in Sentry.
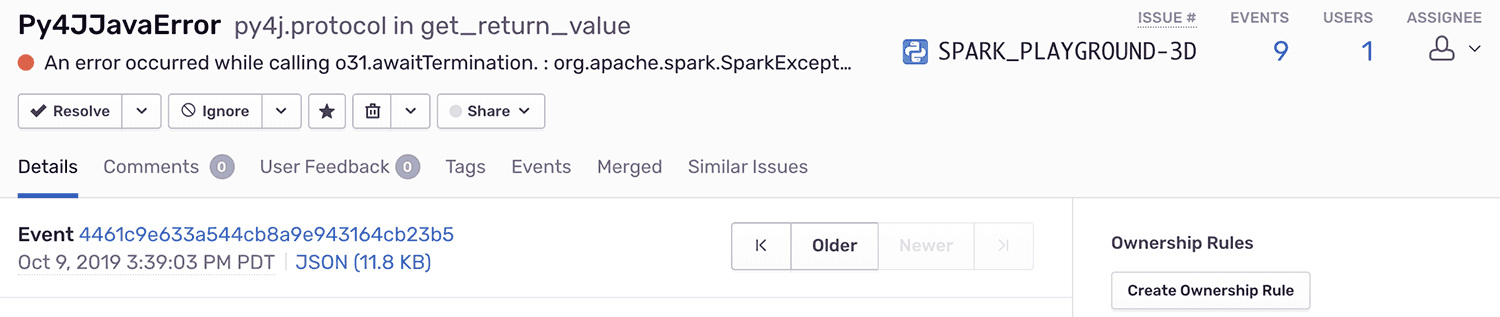
These errors will be tagged with various metadata to help you debug issues faster and more easily.

Breadcrumbs attached to every error also allow you to see what job, stage, and tasks were undertaken before the error happened.

Instrumenting the driver gives us only half the picture. To gain the most insight possible into the error, we should also add the Sentry Spark integration to all of our workers.
Worker
The worker integration requires Spark 2.4 and above.
Create a file called sentry-daemon.py with the following content:
import sentry_sdk
from sentry_sdk.integrations.spark import SparkWorkerIntegration
import pyspark.daemon as original_daemon
if __name__ == '__main__':
sentry_sdk.init("___PUBLIC_DSN___", integrations=[SparkWorkerIntegration()])
original_daemon.manager()To use the Sentry Daemon (which adds Sentry monitoring to each worker), edit your spark-submit command to have the following options.
./bin/spark-submit \
# Sends the sentry_daemon.py file to your Spark clusters
--py-files sentry_daemon.py \
# Configures Spark to use a daemon to execute it's Python workers
--conf spark.python.use.daemon=true \
# Configures Spark to use the sentry custom daemon
--conf spark.python.daemon.module=sentry_daemon \
example-spark-job.pyIn the case of usage of cloud platforms like Google Dataproc or AWS EMR, you can add these configuration options when creating your clusters.
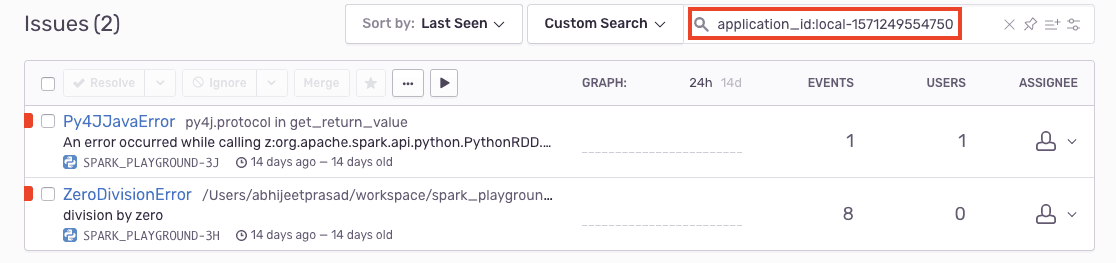
Errors appearing in Sentry should now have a driver and worker error, associated by application_id.
Never settle for just logs again
Be sure to check out our docs to see more advanced usage of the Spark integration.
We have just gotten started integrating Sentry with different data tools as part of our Sentry for Data initiative, so look forward to more integrations coming soon!
If you have any feedback, want more features, or need help setting up the integration, open an issue on the GitHub repository or shout out to our support engineers. They’re here to help. And also to code. But mostly to help.


