The Forensics Of React Server Components (RSCs)


ON THIS PAGE
- The Early Days: React Client-Side Rendering
- The Shift: Server-Side Rendering (SSR)
- The Present: A Hybrid Approach
- The Future: React Server Components
- The Anatomy Of React Server Components
- The Rendering Lifecycle
- RSC Payload
- Streaming
- The Page Load Timeline
- Conclusion
In this article, we’re going to look deeply at React Server Components (RSCs). They are the latest innovation in React’s ecosystem, leveraging both server-side and client-side rendering as well as streaming HTML to deliver content as fast as possible.
We will get really nerdy to get a full understanding of how RSCs fit into the React picture, the level of control they offer over the rendering lifecycle of components, and what page loads look like with RSCs in place.
But before we dive into all of that, I think it’s worth looking back at how React has rendered websites up until this point to set the context for why we need RSCs in the first place.
The Early Days: React Client-Side Rendering
The first React apps were rendered on the client side, i.e., in the browser. As developers, we wrote apps with JavaScript classes as components and packaged everything up using bundlers, like Webpack, in a nicely compiled and tree-shaken heap of code ready to ship in a production environment.
The HTML that returned from the server contained a few things, including:
An HTML document with metadata in the
<head>and a blank<div>in the<body>used as a hook to inject the app into the DOM;JavaScript resources containing React’s core code and the actual code for the web app, which would generate the user interface and populate the app inside of the empty
<div>.
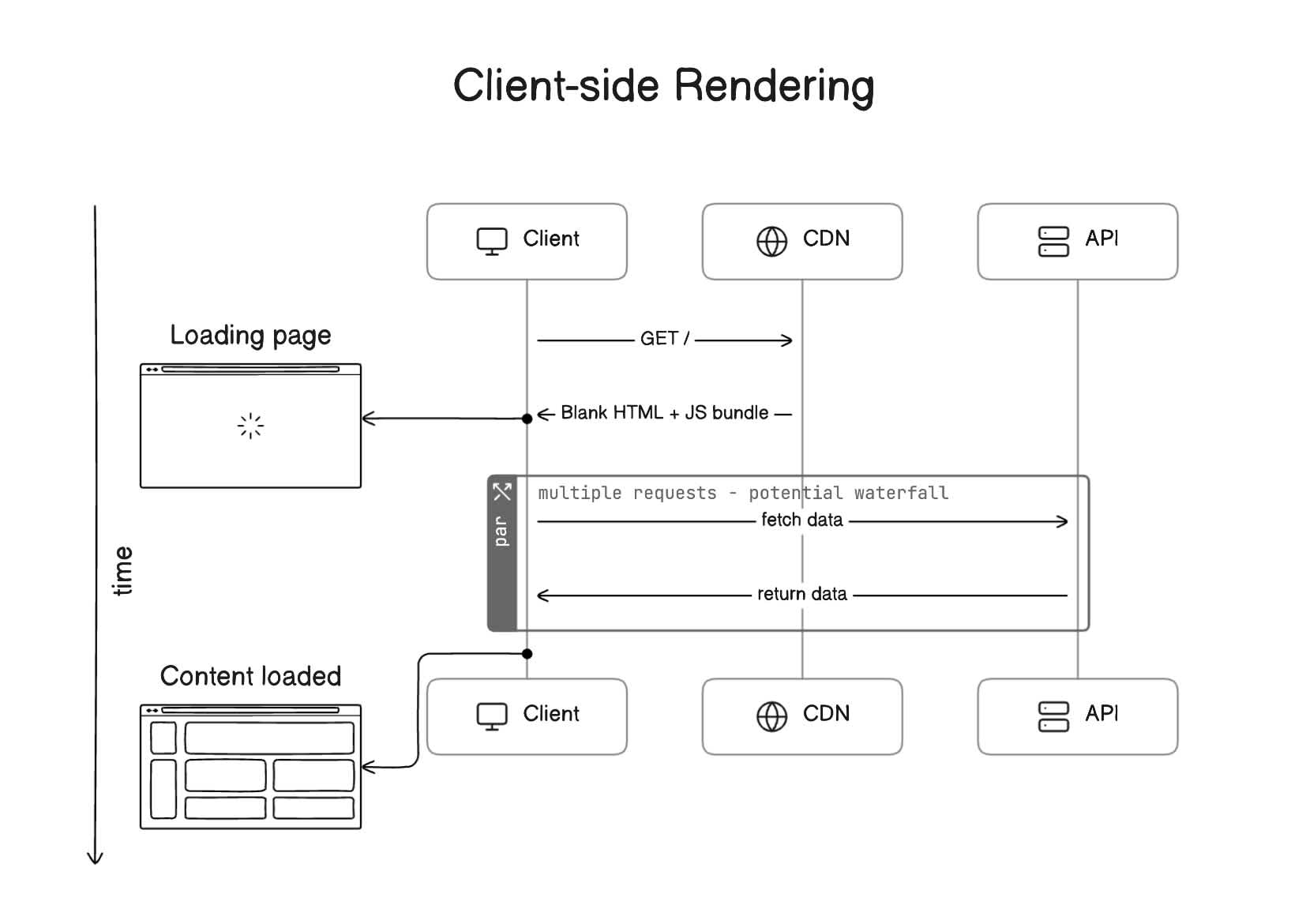
A web app under this process is only fully interactive once JavaScript has fully completed its operations. You can probably already see the tension here that comes with an improved developer experience (DX) that negatively impacts the user experience (UX).
The truth is that there were (and are) pros and cons to CSR in React. Looking at the positives, web applications delivered smooth, quick transitions that reduced the overall time it took to load a page, thanks to reactive components that update with user interactions without triggering page refreshes. CSR lightens the server load and allows us to serve assets from speedy content delivery networks (CDNs) capable of delivering content to users from a server location geographically closer to the user for even more optimized page loads.
There are also not-so-great consequences that come with CSR, most notably perhaps that components could fetch data independently, leading to waterfall network requests that dramatically slow things down. This may sound like a minor nuisance on the UX side of things, but the damage can actually be quite large on a human level. Eric Bailey’s “Modern Health, frameworks, performance, and harm” should be a cautionary tale for all CSR work.
Other negative CSR consequences are not quite as severe but still lead to damage. For example, it used to be that an HTML document containing nothing but metadata and an empty <div> was illegible to search engine crawlers that never get the fully-rendered experience. While that’s solved today, the SEO hit at the time was an anchor on company sites that rely on search engine traffic to generate revenue.
The Shift: Server-Side Rendering (SSR)
Something needed to change. CSR presented developers with a powerful new approach for constructing speedy, interactive interfaces, but users everywhere were inundated with blank screens and loading indicators to get there. The solution was to move the rendering experience from the client to the server. I know it sounds funny that we needed to improve something by going back to the way it was before.
So, yes, React gained server-side rendering (SSR) capabilities. At one point, SSR was such a topic in the React community that it had a moment in the spotlight. The move to SSR brought significant changes to app development, specifically in how it influenced React behavior and how content could be delivered by way of servers instead of browsers.
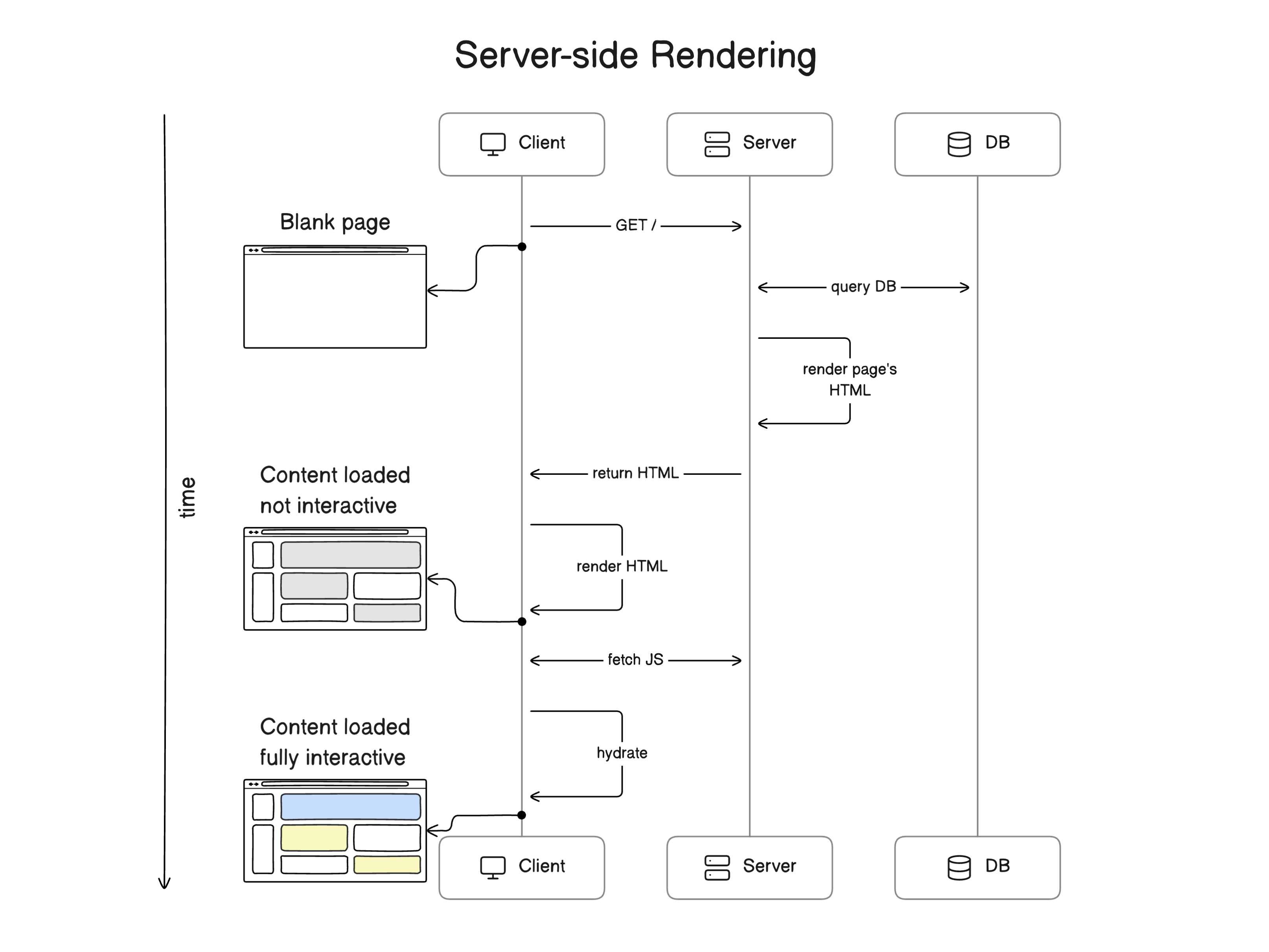
Addressing CSR Limitations
Instead of sending a blank HTML document with SSR, we rendered the initial HTML on the server and sent it to the browser. The browser was able to immediately start displaying the content without needing to show a loading indicator. This significantly improves the First Contentful Paint (FCP) performance metric in Web Vitals.
Server-side rendering also fixed the SEO issues that came with CSR. Since the crawlers received the content of our websites directly, they were then able to index it right away. The data fetching that happens initially also takes place on the server, which is a plus because it’s closer to the data source and can eliminate fetch waterfalls if done properly.
Hydration
SSR has its own complexities. For React to make the static HTML received from the server interactive, it needs to hydrate it. Hydration is the process that happens when React reconstructs its Virtual Document Object Model (DOM) on the client side based on what was in the DOM of the initial HTML.
Note: React maintains its own Virtual DOM because it’s faster to figure out updates on it instead of the actual DOM. It synchronizes the actual DOM with the Virtual DOM when it needs to update the UI but performs the diffing algorithm on the Virtual DOM.
We now have two flavors of Reacts:
A server-side flavor that knows how to render static HTML from our component tree,
A client-side flavor that knows how to make the page interactive.
We’re still shipping React and code for the app to the browser because — in order to hydrate the initial HTML — React needs the same components on the client side that were used on the server. During hydration, React performs a process called reconciliation in which it compares the server-rendered DOM with the client-rendered DOM and tries to identify differences between the two. If there are differences between the two DOMs, React attempts to fix them by rehydrating the component tree and updating the component hierarchy to match the server-rendered structure. And if there are still inconsistencies that cannot be resolved, React will throw errors to indicate the problem. This problem is commonly known as a hydration error.
SSR Drawbacks
SSR is not a silver bullet solution that addresses CSR limitations. SSR comes with its own drawbacks. Since we moved the initial HTML rendering and data fetching to the server, those servers are now experiencing a much greater load than when we loaded everything on the client.
Remember when I mentioned that SSR generally improves the FCP performance metric? That may be true, but the Time to First Byte (TTFB) performance metric took a negative hit with SSR. The browser literally has to wait for the server to fetch the data it needs, generate the initial HTML, and send the first byte. And while TTFB is not a Core Web Vital metric in itself, it influences the metrics. A negative TTFB leads to negative Core Web Vitals metrics.
Another drawback of SSR is that the entire page is unresponsive until client-side React has finished hydrating it. Interactive elements cannot listen and “react” to user interactions before React hydrates them, i.e., React attaches the intended event listeners to them. The hydration process is typically fast, but the internet connection and hardware capabilities of the device in use can slow down rendering by a noticeable amount.
The Present: A Hybrid Approach
So far, we have covered two different flavors of React rendering: CSR and SSR. While the two were attempts to improve one another, we now get the best of both worlds, so to speak, as SSR has branched into three additional React flavors that offer a hybrid approach in hopes of reducing the limitations that come with CSR and SSR.
We’ll look at the first two — static site generation and incremental static regeneration — before jumping into an entire discussion on React Server Components, the third flavor.
Static Site Generation (SSG)
Instead of regenerating the same HTML code on every request, we came up with SSG. This React flavor compiles and builds the entire app at build time, generating static (as in vanilla HTML and CSS) files that are, in turn, hosted on a speedy CDN.
As you might suspect, this hybrid approach to rendering is a nice fit for smaller projects where the content doesn’t change much, like a marketing site or a personal blog, as opposed to larger projects where content may change with user interactions, like an e-commerce site.
SSG reduces the burden on the server while improving performance metrics related to TTFB because the server no longer has to perform heavy, expensive tasks for re-rendering the page.
Incremental Static Regeneration (ISR)
One SSG drawback is having to rebuild all of the app’s code when a content change is needed. The content is set in stone — being static and all — and there’s no way to change just one part of it without rebuilding the whole thing.
The Next.js team created the second hybrid flavor of React that addresses the drawback of complete SSG rebuilds: incremental static regeneration (ISR). The name says a lot about the approach in that ISR only rebuilds what’s needed instead of the entire thing. We generate the “initial version” of the page statically during build time but are also able to rebuild any page containing stale data after a user lands on it (i.e., the server request triggers the data check).
From that point on, the server will serve new versions of that page statically in increments when needed. That makes ISR a hybrid approach that is neatly positioned between SSG and traditional SSR.
At the same time, ISR does not address the “stale content” symptom, where users may visit a page before it has finished being generated. Unlike SSG, ISR needs an actual server to regenerate individual pages in response to a user’s browser making a server request. That means we lose the valuable ability to deploy ISR-based apps on a CDN for optimized asset delivery.
The Future: React Server Components
Up until this point, we’ve juggled between CSR, SSR, SSG, and ISR approaches, where all make some sort of trade-off, negatively affecting performance, development complexity, and user experience. Newly introduced React Server Components (RSC) aim to address most of these drawbacks by allowing us — the developer — to choose the right rendering strategy for each individual React component.
RSCs can significantly reduce the amount of JavaScript shipped to the client since we can selectively decide which ones to serve statically on the server and which render on the client side. There’s a lot more control and flexibility for striking the right balance for your particular project.
Note: It’s important to keep in mind that as we adopt more advanced architectures, like RSCs, monitoring solutions become invaluable. Sentry offers robust performance monitoring and error-tracking capabilities that help you keep an eye on the real-world performance of your RSC-powered application. Sentry also helps you gain insights into how your releases are performing and how stable they are, which is yet another crucial feature to have while migrating your existing applications to RSCs. Implementing Sentry in an RSC-enabled framework like Next.js is as easy as running a single terminal command.
But what exactly is an RSC? Let’s pick one apart to see how it works under the hood.
The Anatomy Of React Server Components
This new approach introduces two types of rendering components: Server Components and Client Components. The differences between these two are not how they function but where they execute and the environments they’re designed for. At the time of this writing, the only way to use RSCs is through React frameworks. And at the moment, there are only three frameworks that support them: Next.js, Gatsby, and RedwoodJS.
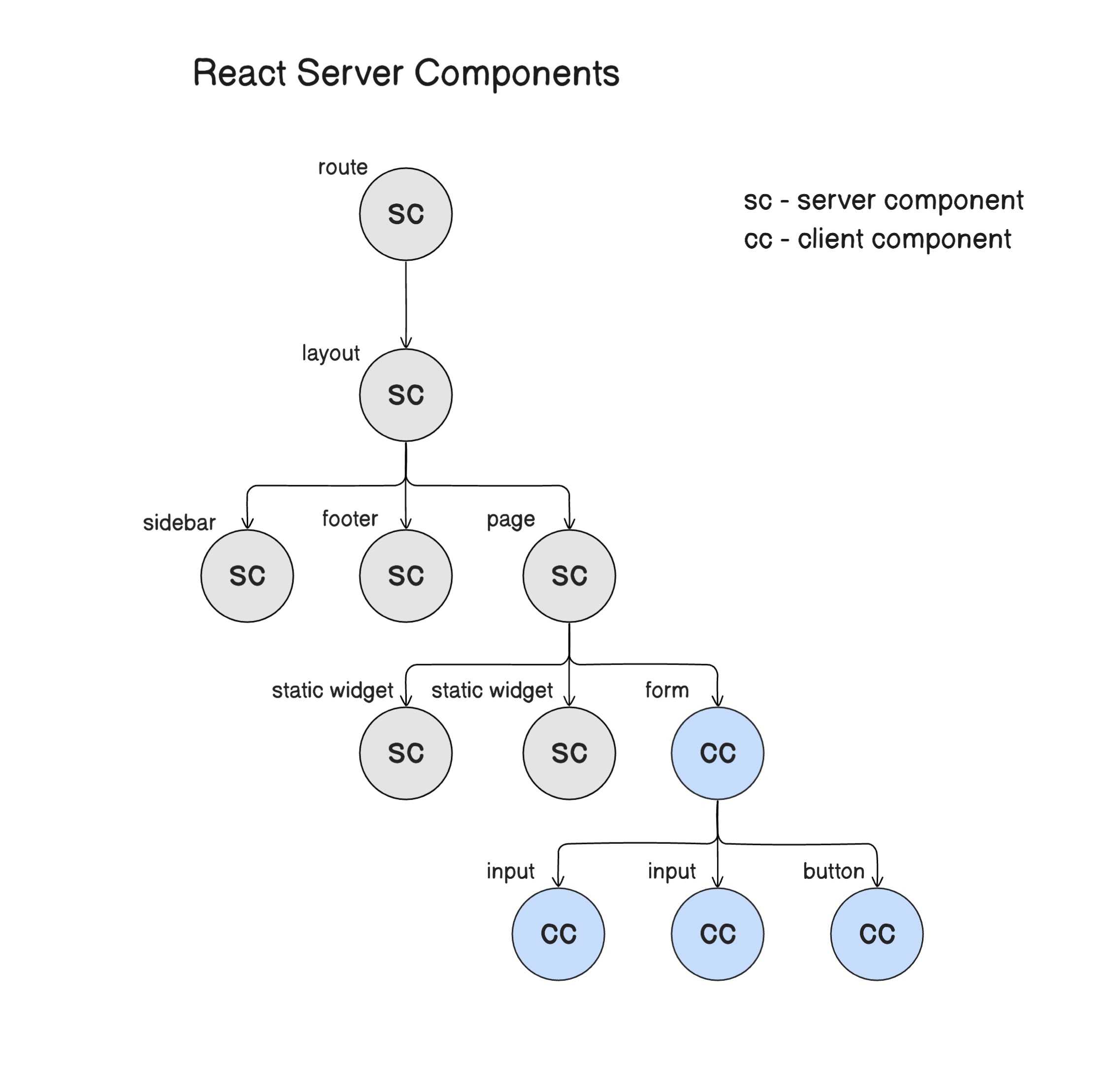
Server Components
Server Components are designed to be executed on the server, and their code is never shipped to the browser. The HTML output and any props they might be accepting are the only pieces that are served. This approach has multiple performance benefits and user experience enhancements:
Server Components allow for large dependencies to remain on the server side.
Imagine using a large library for a component. If you’re executing the component on the client side, it means that you’re also shipping the full library to the browser. With Server Components, you’re only taking the static HTML output and avoiding having to ship any JavaScript to the browser. Server Components are truly static, and they remove the whole hydration step.Server Components are located much closer to the data sources — e.g., databases or file systems — they need to generate code.
They also leverage the server’s computational power to speed up compute-intensive rendering tasks and send only the generated results back to the client. They are also generated in a single pass, which avoids request waterfalls and HTTP round trips.Server Components safely keep sensitive data and logic away from the browser.
That’s thanks to the fact that personal tokens and API keys are executed on a secure server rather than the client.The rendering results can be cached and reused between subsequent requests and even across different sessions.
This significantly reduces rendering time, as well as the overall amount of data that is fetched for each request.
This architecture also makes use of HTML streaming, which means the server defers generating HTML for specific components and instead renders a fallback element in their place while it works on sending back the generated HTML. Streaming Server Components wrap components in <Suspense tags that provide a fallback value. The implementing framework uses the fallback initially but streams the newly generated content when it‘s ready. We’ll talk more about streaming, but let’s first look at Client Components and compare them to Server Components.
Client Components
Client Components are the components we already know and love. They’re executed on the client side. Because of this, Client Components are capable of handling user interactions and have access to the browser APIs like localStorage and geolocation.
The term “Client Component” doesn’t describe anything new; they merely are given the label to help distinguish the “old” CSR components from Server Components. Client Components are defined by a "use client" directive at the top of their files.
"use client"
export default function LikeButton() {
const likePost = () => {
// ...
}
return (
<button onClick={likePost}>Like</button>
)
}In Next.js, all components are Server Components by default. That’s why we need to explicitly define our Client Components with "use client". There’s also a "use server" directive, but it’s used for Server Actions (which are RPC-like actions that invoked from the client, but executed on the server). You don’t use it to define your Server Components.
You might (rightfully) assume that Client Components are only rendered on the client, but Next.js renders Client Components on the server to generate the initial HTML. As a result, browsers can immediately start rendering them and then perform hydration later.
The Relationship Between Server Components and Client Components
Client Components can only explicitly import other Client Components. In other words, we’re unable to import a Server Component into a Client Component because of re-rendering issues. But we can have Server Components in a Client Component’s subtree — only passed through the children prop. Since Client Components live in the browser and they handle user interactions or define their own state, they get to re-render often. When a Client Component re-renders, so will its subtree. But if its subtree contains Server Components, how would they re-render? They don’t live on the client side. That’s why the React team put that limitation in place.
But hold on! We actually can import Server Components into Client Components. It’s just not a direct one-to-one relationship because the Server Component will be converted into a Client Component. If you’re using server APIs that you can’t use in the browser, you’ll get an error; if not — you’ll have a Server Component whose code gets “leaked” to the browser.
This is an incredibly important nuance to keep in mind as you work with RSCs.
The Rendering Lifecycle
Here’s the order of operations that Next.js takes to stream contents:
The app router matches the page’s URL to a Server Component, builds the component tree, and instructs the server-side React to render that Server Component and all of its children components.
During render, React generates an “RSC Payload”. The RSC Payload informs Next.js about the page and what to expect in return, as well as what to fall back to during a
<Suspense>.If React encounters a suspended component, it pauses rendering that subtree and uses the suspended component’s fallback value.
When React loops through the last static component, Next.js prepares the generated HTML and the RSC Payload before streaming it back to the client through one or multiple chunks.
The client-side React then uses the instructions it has for the RSC Payload and client-side components to render the UI. It also hydrates each Client Component as they load.
The server streams in the suspended Server Components as they become available as an RSC Payload. Children of Client Components are also hydrated at this time if the suspended component contains any.
We will look at the RSC rendering lifecycle from the browser’s perspective momentarily. For now, the following figure illustrates the outlined steps we covered.
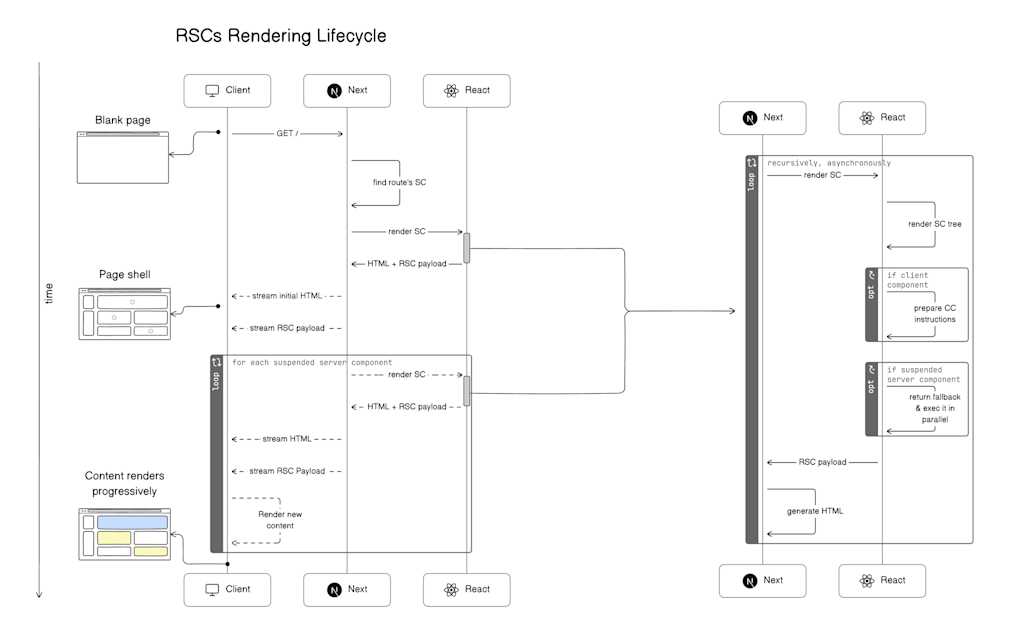
We’ll see this operation flow from the browser’s perspective in just a bit.
RSC Payload
The RSC payload is a special data format that the server generates as it renders the component tree, and it includes the following:
The rendered HTML,
Placeholders where the Client Components should be rendered,
References to the Client Components’ JavaScript files,
Instructions on which JavaScript files it should invoke,
Any props passed from a Server Component to a Client Component.
There’s no reason to worry much about the RSC payload, but it’s worth understanding what exactly the RSC payload contains. Let’s examine an example (truncated for brevity) from a demo app I created:
1:HL["/_next/static/media/c9a5bc6a7c948fb0-s.p.woff2","font",{"crossOrigin":"","type":"font/woff2"}]
2:HL["/_next/static/css/app/layout.css?v=1711137019097","style"]
0:"$L3"
4:HL["/_next/static/css/app/page.css?v=1711137019097","style"]
5:I["(app-pages-browser)/./node_modules/next/dist/client/components/app-router.js",["app-pages-internals","static/chunks/app-pages-internals.js"],""]
8:"$Sreact.suspense"
a:I["(app-pages-browser)/./node_modules/next/dist/client/components/layout-router.js",["app-pages-internals","static/chunks/app-pages-internals.js"],""]
b:I["(app-pages-browser)/./node_modules/next/dist/client/components/render-from-template-context.js",["app-pages-internals","static/chunks/app-pages-internals.js"],""]
d:I["(app-pages-browser)/./src/app/global-error.jsx",["app/global-error","static/chunks/app/global-error.js"],""]
f:I["(app-pages-browser)/./src/components/clearCart.js",["app/page","static/chunks/app/page.js"],"ClearCart"]
7:["$","main",null,{"className":"page_main__GlU4n","children":[["$","$Lf",null,{}],["$","$8",null,{"fallback":["$","p",null,{"children":"🌀 loading products..."}],"children":"$L10"}]]}]
c:[["$","meta","0",{"name":"viewport","content":"width=device-width, initial-scale=1"}]...
9:["$","p",null,{"children":["🛍️ ",3]}]
11:I["(app-pages-browser)/./src/components/addToCart.js",["app/page","static/chunks/app/page.js"],"AddToCart"]
10:["$","ul",null,{"children":[["$","li","1",{"children":["Gloves"," - $",20,["$...To find this code in the demo app, open your browser’s developer tools at the Elements tab and look at the <script> tags at the bottom of the page. They’ll contain lines like:
self.__next_f.push([1,"PAYLOAD_STRING_HERE"]).Every line from the snippet above is an individual RSC payload. You can see that each line starts with a number or a letter, followed by a colon, and then an array that’s sometimes prefixed with letters. We won’t get into too deep in detail as to what they mean, but in general:
HLpayloads are called “hints” and link to specific resources like CSS and fonts.Ipayloads are called “modules,” and they invoke specific scripts. This is how Client Components are being loaded as well. If the Client Component is part of the main bundle, it’ll execute. If it’s not (meaning it’s lazy-loaded), a fetcher script is added to the main bundle that fetches the component’s CSS and JavaScript files when it needs to be rendered. There’s going to be anIpayload sent from the server that invokes the fetcher script when needed."$"payloads are DOM definitions generated for a certain Server Component. They are usually accompanied by actual static HTML streamed from the server. That’s what happens when a suspended component becomes ready to be rendered: the server generates its static HTML and RSC Payload and then streams both to the browser.
Streaming
Streaming allows us to progressively render the UI from the server. With RSCs, each component is capable of fetching its own data. Some components are fully static and ready to be sent immediately to the client, while others require more work before loading. Based on this, Next.js splits that work into multiple chunks and streams them to the browser as they become ready. So, when a user visits a page, the server invokes all Server Components, generates the initial HTML for the page (i.e., the page shell), replaces the “suspended” components’ contents with their fallbacks, and streams all of that through one or multiple chunks back to the client.
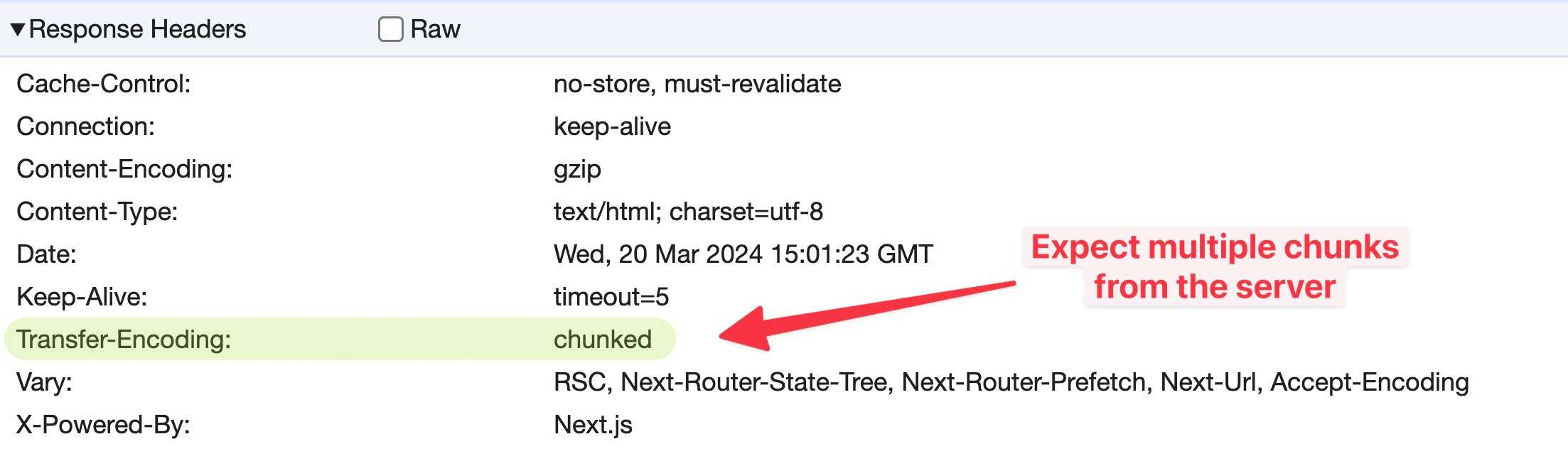
The server returns a Transfer-Encoding: chunked header that lets the browser know to expect streaming HTML. This prepares the browser for receiving multiple chunks of the document, rendering them as it receives them. We can actually see the header when opening Developer Tools at the Network tab. Trigger a refresh and click on the document request.
We can also debug the way Next.js sends the chunks in a terminal with the curl command:
curl -D - --raw localhost:3000 > chunked-response.txt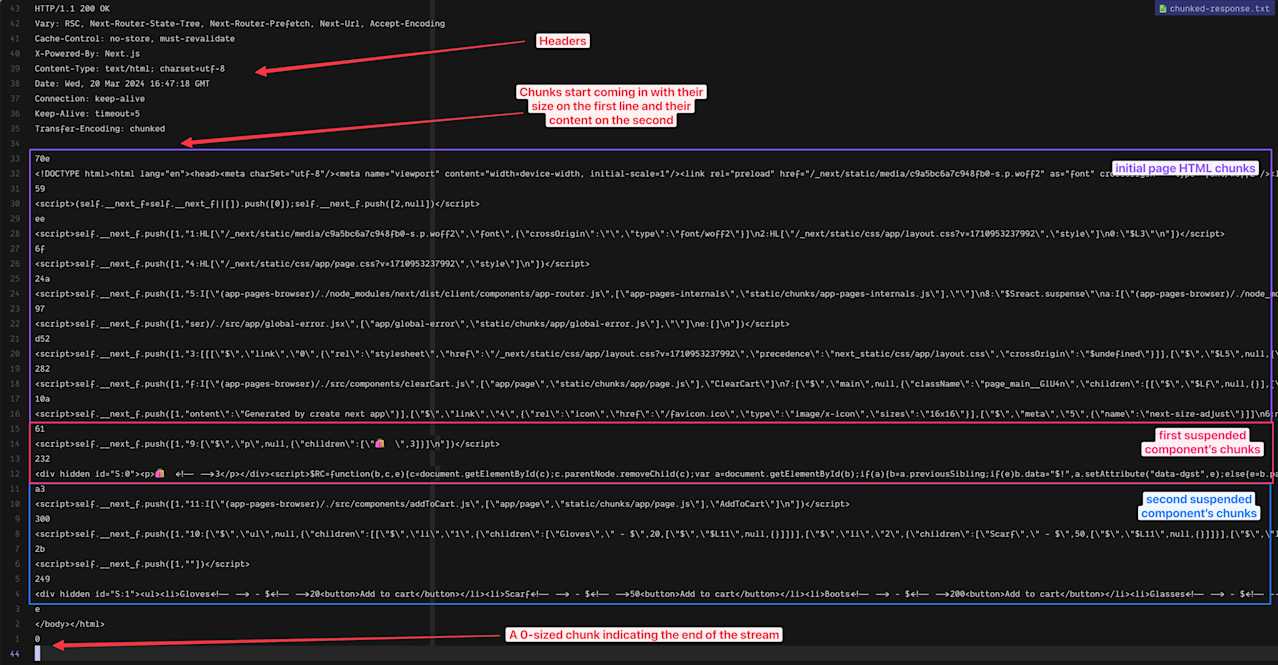
You probably see the pattern. For each chunk, the server responds with the chunk’s size before sending the chunk’s contents. Looking at the output, we can see that the server streamed the entire page in 16 different chunks. At the end, the server sends back a zero-sized chunk, indicating the end of the stream.
The first chunk starts with the <!DOCTYPE html> declaration. The second-to-last chunk, meanwhile, contains the closing </body> and </html> tags. So, we can see that the server streams the entire document from top to bottom, then pauses to wait for the suspended components, and finally, at the end, closes the body and HTML before it stops streaming.
Even though the server hasn’t completely finished streaming the document, the browser’s fault tolerance features allow it to draw and invoke whatever it has at the moment without waiting for the closing </body> and </html> tags.
Suspending Components
We learned from the render lifecycle that when a page is visited, Next.js matches the RSC component for that page and asks React to render its subtree in HTML. When React stumbles upon a suspended component (i.e., async function component), it grabs its fallback value from the <Suspense> component (or the loading.js file if it’s a Next.js route), renders that instead, then continues loading the other components. Meanwhile, the RSC invokes the async component in the background, which is streamed later as it finishes loading.
At this point, Next.js has returned a full page of static HTML that includes either the components themselves (rendered in static HTML) or their fallback values (if they’re suspended). It takes the static HTML and RSC payload and streams them back to the browser through one or multiple chunks.
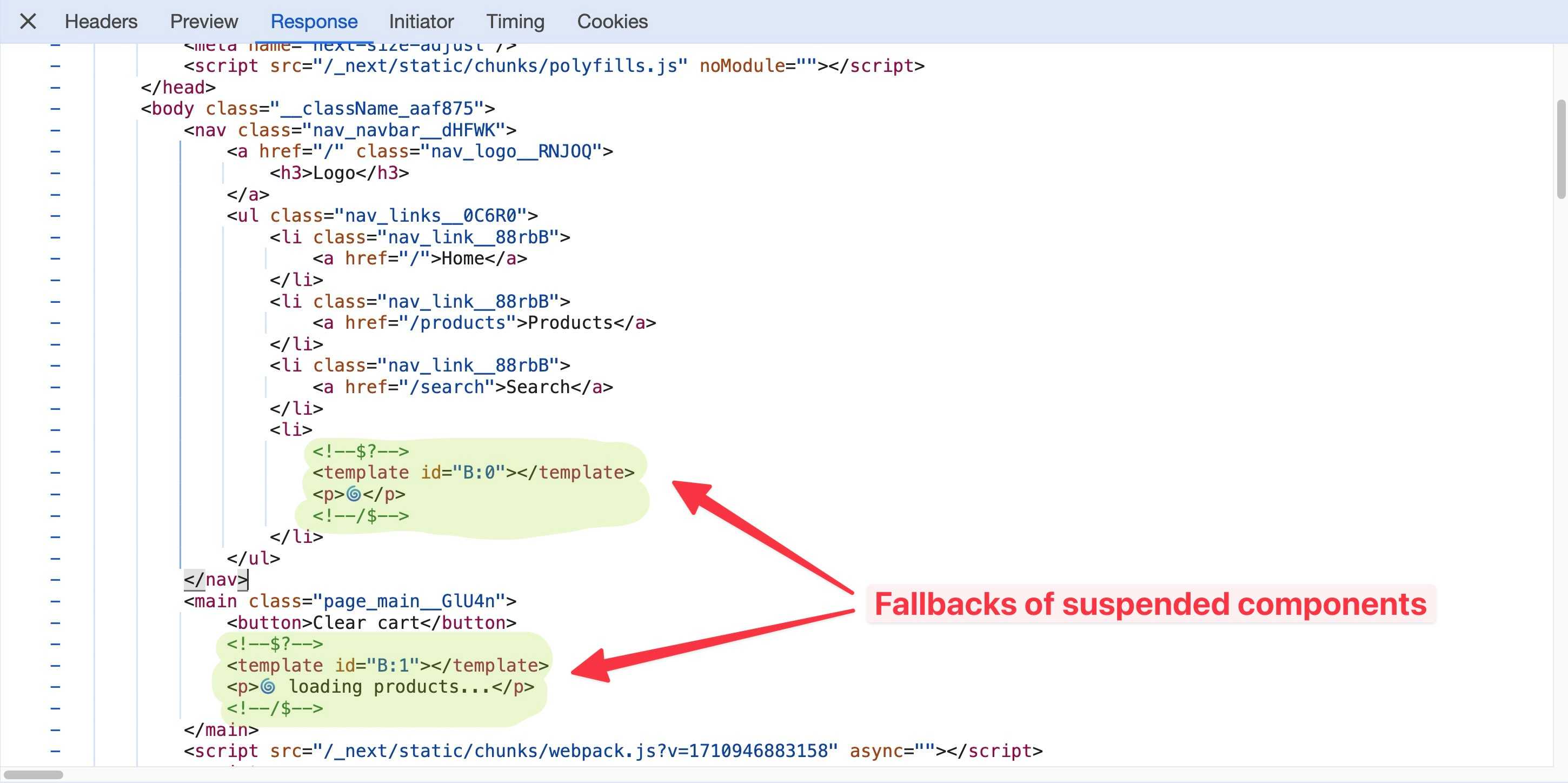
As the suspended components finish loading, React generates HTML recursively while looking for other nested <Suspense> boundaries, generates their RSC payloads and then lets Next.js stream the HTML and RSC Payload back to the browser as new chunks. When the browser receives the new chunks, it has the HTML and RSC payload it needs and is ready to replace the fallback element from the DOM with the newly-streamed HTML. And so on.
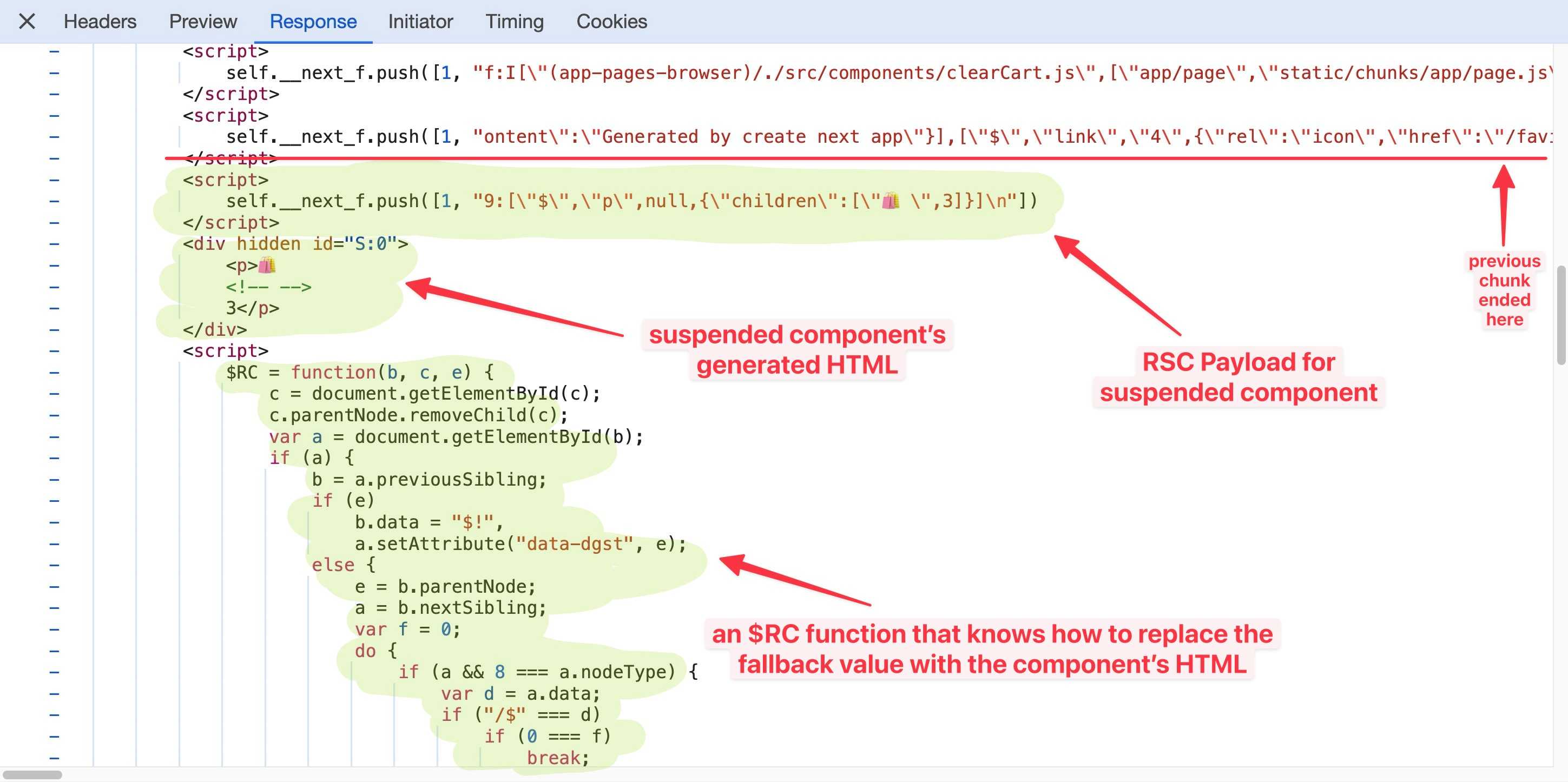
In the last two images, notice how the fallback elements have a unique ID in the form of B:0, B:1, and so on, while the actual components have a similar ID in a similar form: S:0 and S:1, and so on.
Along with the first chunk that contains a suspended component’s HTML, the server also ships an $RC function (i.e., completeBoundary from React’s source code) that knows how to find the B:0 fallback element in the DOM and replace it with the S:0 template it received from the server. That’s the “replacer” function that lets us see the component contents when they arrive in the browser.
The entire page eventually finishes loading, chunk by chunk.
Lazy-Loading Components
If a suspended Server Component contains a lazy-loaded Client Component, Next.js will also send an RSC payload chunk containing instructions on how to fetch and load the lazy-loaded component’s code. This represents a significant performance improvement because the page load isn’t dragged out by JavaScript, which might not even be loaded during that session.
At the time I’m writing this, the dynamic method to lazy-load a Client Component in a Server Component in Next.js does not work as you might expect. To effectively lazy-load a Client Component, put it in a “wrapper” Client Component that uses the dynamic method itself to lazy-load the actual Client Component. The wrapper will be turned into a script that fetches and loads the Client Component’s JavaScript and CSS files at the time they’re needed.
TD;DR
I know that’s a lot of plates spinning and pieces moving around at various times. What it boils down to, however, is that a page visit triggers Next.js to render as much HTML as it can, using the fallback values for any suspended components, and then sends that to the browser. Meanwhile, Next.js triggers the suspended async components and gets them formatted in HTML and contained in RSC Payloads that are streamed to the browser, one by one, along with an $RC script that knows how to swap things out.
The Page Load Timeline
By now, we should have a solid understanding of how RSCs work, how Next.js handles their rendering, and how all the pieces fit together. In this section, we’ll zoom in on what exactly happens when we visit an RSC page in the browser.
The Initial Load
As we mentioned in the TL;DR section above, when visiting a page, Next.js will render the initial HTML minus the suspended component and stream it to the browser as part of the first streaming chunks.
To see everything that happens during the page load, we’ll visit the “Performance” tab in Chrome DevTools and click on the “reload” button to reload the page and capture a profile. Here’s what that looks like:
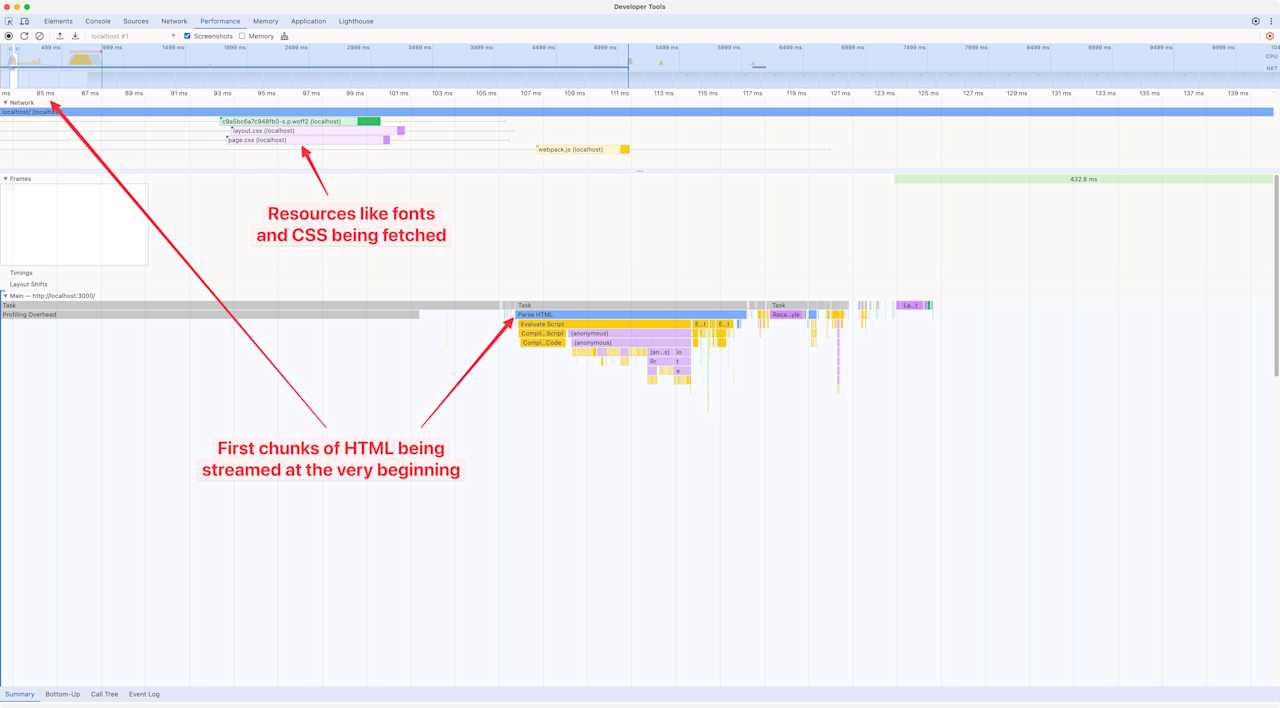
When we zoom in at the very beginning, we can see the first “Parse HTML” span. That’s the server streaming the first chunks of the document to the browser. The browser has just received the initial HTML, which contains the page shell and a few links to resources like fonts, CSS files, and JavaScript. The browser starts to invoke the scripts.
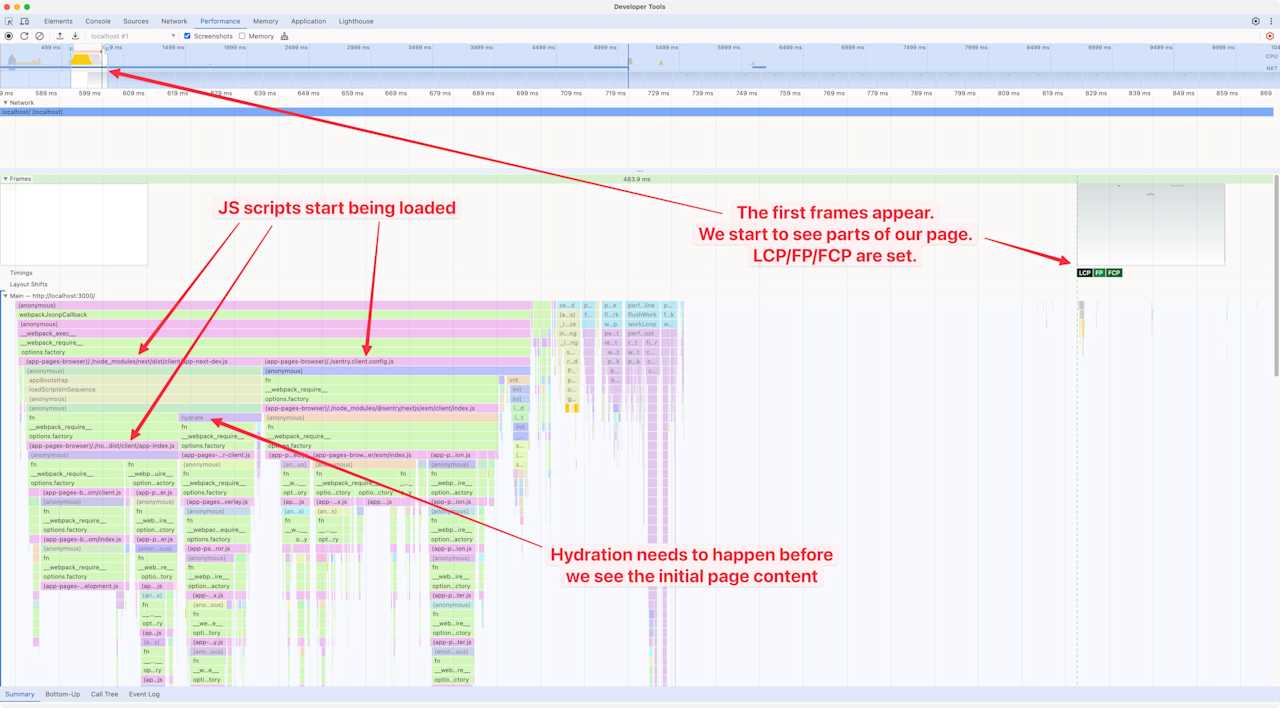
After some time, we start to see the page’s first frames appear, along with the initial JavaScript scripts being loaded and hydration taking place. If you look at the frame closely, you’ll see that the whole page shell is rendered, and “loading” components are used in the place where there are suspended Server Components. You might notice that this takes place around 800ms, while the browser started to get the first HTML at 100ms. During those 700ms, the browser is continuously receiving chunks from the server.
Bear in mind that this is a Next.js demo app running locally in development mode, so it’s going to be slower than when it’s running in production mode.
The Suspended Component
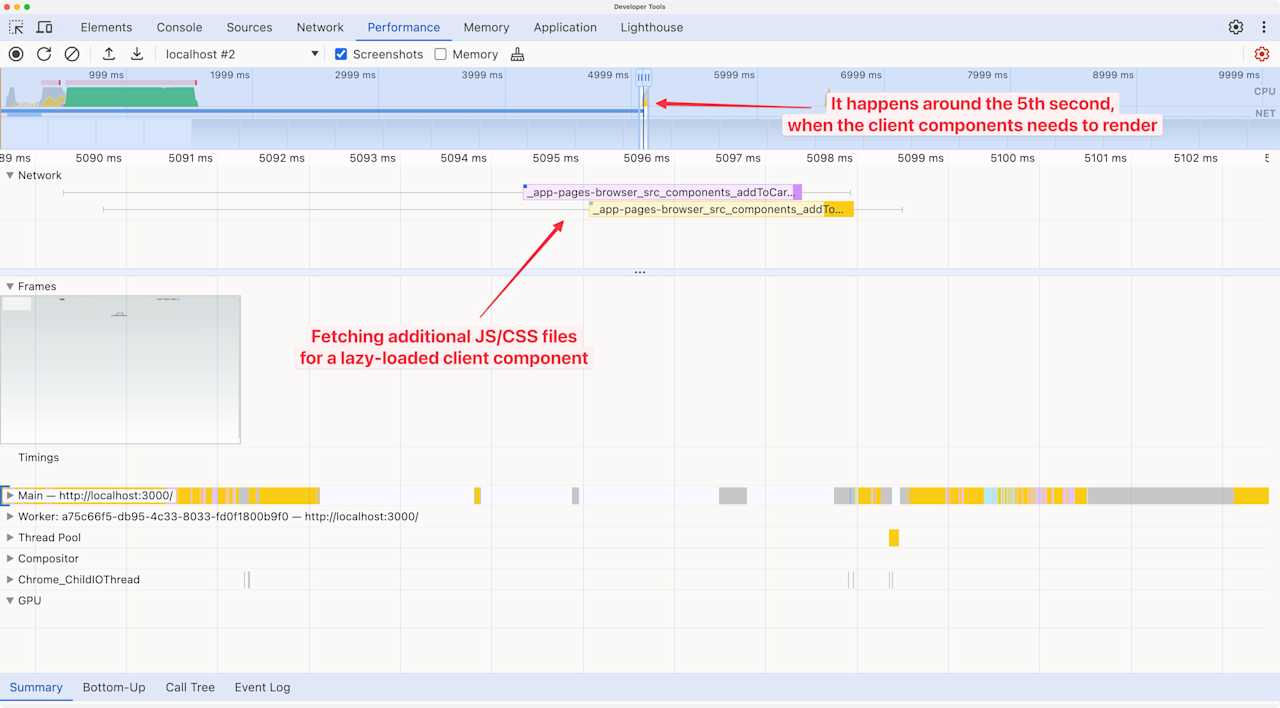
Fast forward few seconds and we see another “Parse HTML” span in the page load timeline, but this one it indicates that a suspended Server Component finished loading and is being streamed to the browser.
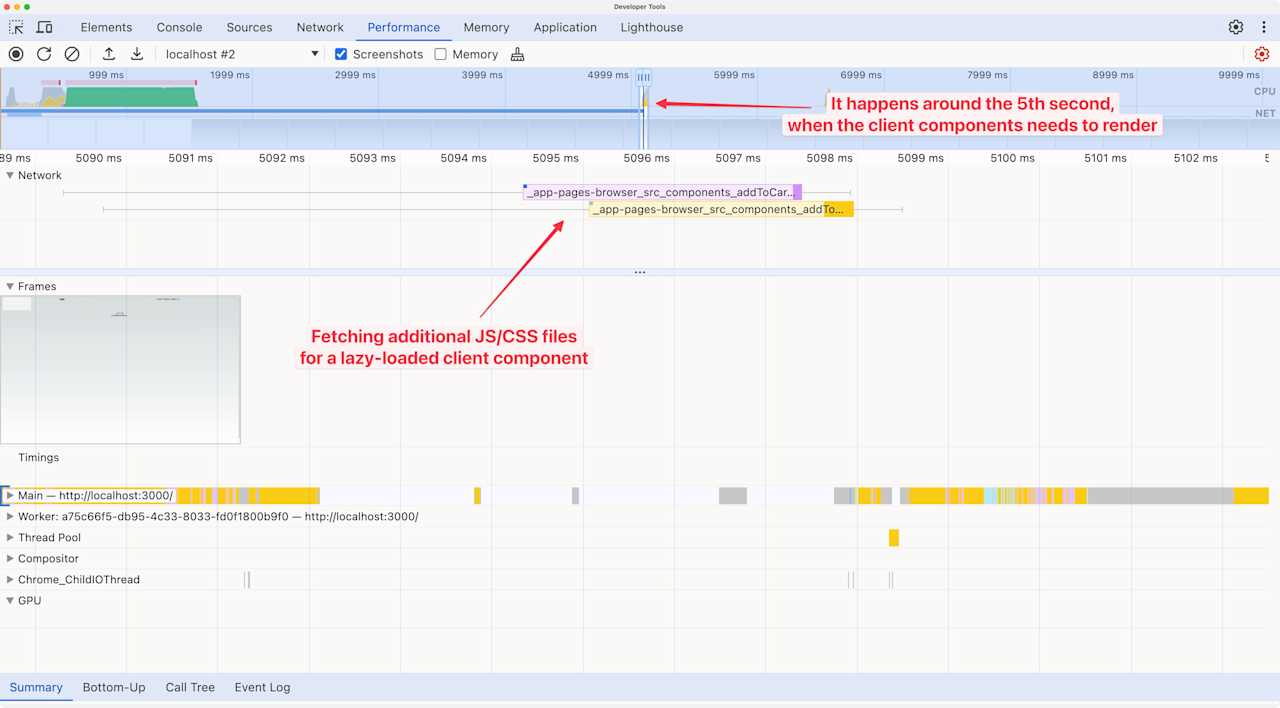
We can also see that a lazy-loaded Client Component is discovered at the same time, and it contains CSS and JavaScript files that need to be fetched. These files weren’t part of the initial bundle because the component isn’t needed until later on; the code is split into their own files.
This way of code-splitting certainly improves the performance of the initial page load. It also makes sure that the Client Component’s code is shipped only if it’s needed. If the Server Component (which acts as the Client Component’s parent component) throws an error, then the Client Component does not load. It doesn’t make sense to load all of its code before we know whether it will load or not.
The image above shows the DOMContentLoaded event is reported at the end of the page load timeline. And, just before that, we can see that the localhost HTTP request comes to an end. That means the server has likely sent the last zero-sized chunk, indicating to the client that the data is fully transferred and that the streaming communication can be closed.
The End Result
The main localhost HTTP request took around five seconds, but thanks to streaming, we began seeing page contents load much earlier than that. If this was a traditional SSR setup, we would likely be staring at a blank screen for those five seconds before anything arrives. On the other hand, if this was a traditional CSR setup, we would likely have shipped a lot more of JavaScript and put a heavy burden on both the browser and network.
This way, however, the app was fully interactive in those five seconds. We were able to navigate between pages and interact with Client Components that have loaded as part of the initial main bundle. This is a pure win from a user experience standpoint.
Conclusion
RSCs mark a significant evolution in the React ecosystem. They leverage the strengths of server-side and client-side rendering while embracing HTML streaming to speed up content delivery. This approach not only addresses the SEO and loading time issues we experience with CSR but also improves SSR by reducing server load, thus enhancing performance.
I’ve refactored the same RSC app I shared earlier so that it uses the Next.js Page router with SSR. The improvements in RSCs are significant:
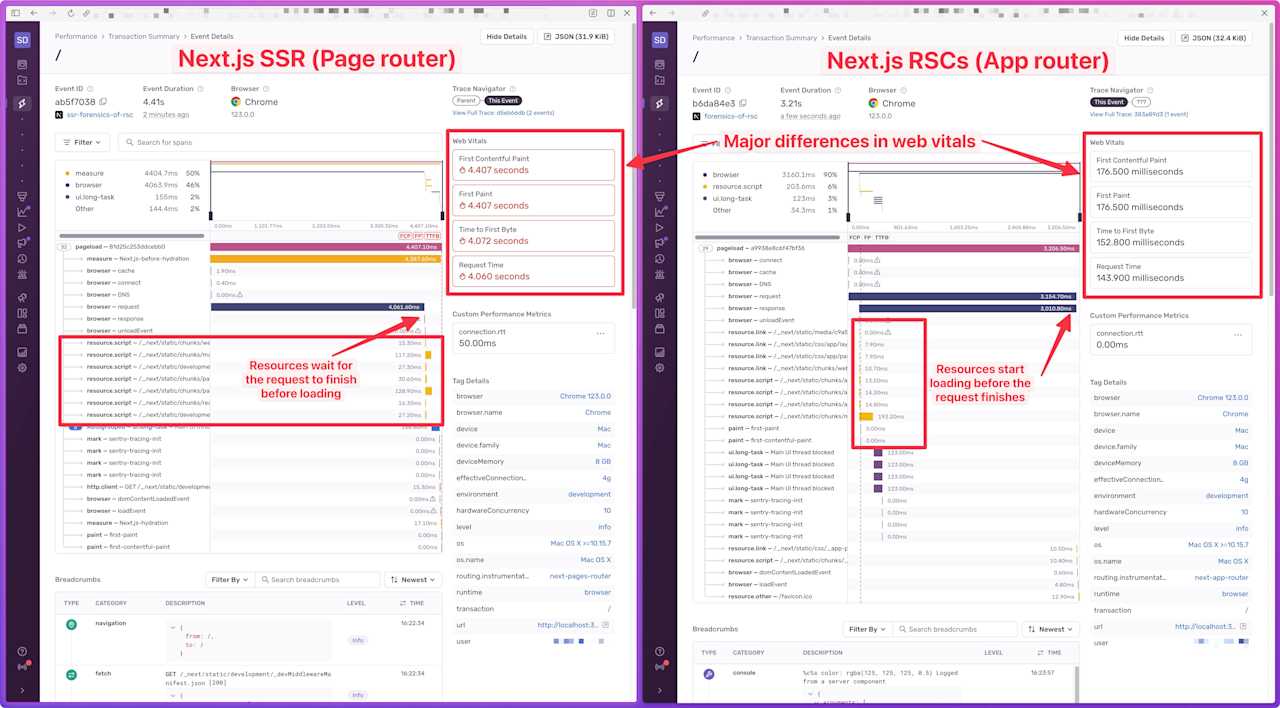
Looking at these two reports I pulled from Sentry, we can see that streaming allows the page to start loading its resources before the actual request finishes. This significantly improves the Web Vitals metrics, which we see when comparing the two reports.
The conclusion: Users enjoy faster, more reactive interfaces with an architecture that relies on RSCs.
The RSC architecture introduces two new component types: Server Components and Client Components. This division helps React and the frameworks that rely on it — like Next.js — streamline content delivery while maintaining interactivity.
However, this setup also introduces new challenges in areas like state management, authentication, and component architecture. Exploring those challenges is a great topic for another blog post!
Despite these challenges, the benefits of RSCs present a compelling case for their adoption. We definitely will see guides published on how to address RSC’s challenges as they mature, but, in my opinion, they already look like the future of rendering practices in modern web development.


