rb: A Redis parallelization toolkit for Python
rb: A Redis parallelization toolkit for Python

We love Redis at Sentry. Since the early days it has driven many parts of our system, allowing users to improve error monitoring with rate limiting and caching, as well as powering the entirety of our time series data storage. We have enough data in Redis that a single machine won't cut it.
Previously we had been using the Nydus
library to communicate with multiple independent Redis nodes. It is based on the idea that you can route individual requests to individual nodes and it largely automates this process for you. Tools like twemproxy achieve a similar result, but they do it via a proxy layer whereas Nydus does it at the application level (thus avoiding an infrastructure dependency).
One of the most useful features of Nydus is the ability to issue many requests in parallel. Given a large set of operations we want to execute them in the most efficient way possible. At a basic level that means parallelizing operations. Nydus does this using Python’s internal threading and a simple worker pool.
Executing Operations in Parallel
Sentry exposes numerous API endpoints where we fetch hundreds of Redis keys
from different nodes. To do that you run some code akin to:
def look_up_keys(keys):
results = []
for key in keys:
client_for_host = get_host_for_key(key)
results.append(client_for_host.get(key))
return resultsNow the problem here is that you’re doing a single request per key. At the very least you’d want to pipeline all requests that go to the same node. Even better would be if you could fetch from different hosts in parallel. Nydus does that and more for you in a very simple abstraction:
def look_up_keys(keys):
results = []
# when the context manager exits the commands are executed
# and the resulting object (a sort-of proxy to a promise) gets
# assigned the result
with cluster.map() as conn:
for key in keys:
results.append(conn.get(key))
return resultsWhat we didn’t expect was how much slower these lookups became after increasing the node count. Nydus internally uses threads for concurrency to achieve parallel data fetching and that turns out to be problematic in Python. There’s a number of problems here, but they all boil down to performance. In our case we consistently saw locking as being the number one bottleneck. This is to be expected as the way a threaded worker pool operates is by using a thread-safe queue, thus consistently taking out locks.
Changing Nydus to not use threads wasn’t an easy task because it doesn’t just support Redis, but also other databases like Cassandra. It's a very high level library that aims to provide basic cluster management so a lot of the code is generalized to support other connections. Given this it becomes very hard to support changing the threading abstraction as underlying connection libraries function differently.
A Better Approach
After determining that the threading (and resulting locks) were our biggest issue we decided to create a new library which would take a better approach. The new library we wrote, rb (Redis Blaster) only works with Redis, but that offers us a few advantages.
We switched the parallel query implementation to use a select loop (select/poll/kqueue). This allows us to reuse the entire connection and client system from the Python Redis library. It also means no thread spawning, no locking, and much higher performance.
Additionally the routing layer was overhauled to support more correct behavior. Because rb knows about the structure of all Redis commands, it correctly knows which parameters are keys and which are not. This ended up pointing out some potentially bad uses of Nydus in our codebase. Now if you try to issue a command like MGET (to get multiple keys) and you pass more than one key, the library will error out instead of producing garbage.
Nydus is dead. Long live rb.
Improving Routing
The most common operation is to work with commands that operate on keys
which get routed to one of the many nodes. For this the map() function
comes in handy which works similar to the one in Nydus:
results = []
with cluster.map() as client:
for key in range(100):
results.append(client.get(key))
print 'Sum: %s' % sum(int(x.value or 0) for x in results)Something else we found ourselves doing frequently was running commands across all hosts. This was more complex in Nydus as you effectively needed to iterate each host and run the command on it. With rb you can do that through the all() API. For instance to delete all Redis server's databases you can do this:
# a common pattern for our testsuite fixtures
with cluster.all() as client:
client.flushdb()Simplifying Promises
As part of the process we decided to also clean up the API. We use the same ideas as Nydus, but use an explicit promise object instead of the proxy. This is both more explicit but also less error prone, and once again gives us a slight performance boost. Nydus used to use proxy objects that would eventually resolve to the value that comes back from Redis but this required being careful when to use it, and to type convert it before passing it on to other APIs that might be either confused by the promise or that would hold on to it and create a small memory leak.
The promises are heavily inspired by the ES6 implementation, with a slightly modified API to make it work better in Python. While the lack of anonymous block functions makes Promises a little less elegant in Python, for our use cases simple lambda functions can go a long way.
In the end, the API is very easy to reason about:
results = []
with cluster.map() as client:
for key in range(100):
client.get(key).then(lambda x: results.append(int(x or 0)))In Production
We set off on this adventure to improve the response time on a very specific endpoint. Once we got it out there we were pleasantly surprised to see noticeable impact on other pages, such as our store API endpoint (the majority of Sentry’s requests):
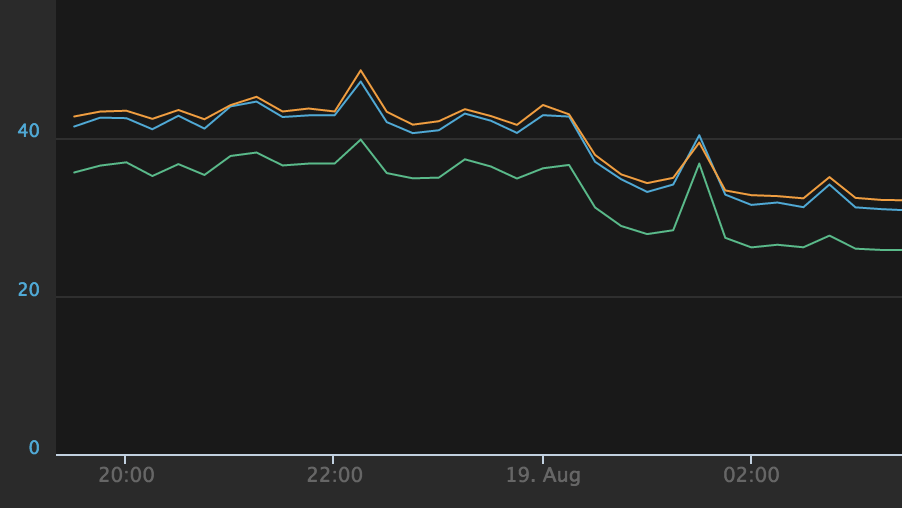
The real kicker here is that this endpoint does far fewer operations than many of our others, but we still managed to get a very measurable performance boost out of the change.
Get it on Github
rb is available for general consumption under the Apache 2 License. Documentation can be found on rb.readthedocs.org.
We would love to get your feedback and hope it's as useful to you as to us.


