Go-Getting Lazy-Loading
Go-Getting Lazy-Loading


Lazy-loading is the most ironic term in programming. That’s because, instead of eating its third bowl of cereal on the couch, what lazy-loading actually does is make your User Interface more efficient.
And efficient UI is important to us at Sentry. We don’t want our customers tapping their feet and pointing to their imaginary watch while waiting for their page to load. Unfortunately, rendering the sheer amount of real-time data that Sentry provides — error frequency, release data, latency, throughput — can be a problem.
Now, as developers, we know that most problems have already been solved somewhere (by somewhere we mean Stack Overflow). Problem was, no one else had our problem; that is, no other error monitoring platform is capable of processing (and rendering) the amount of data that we do.
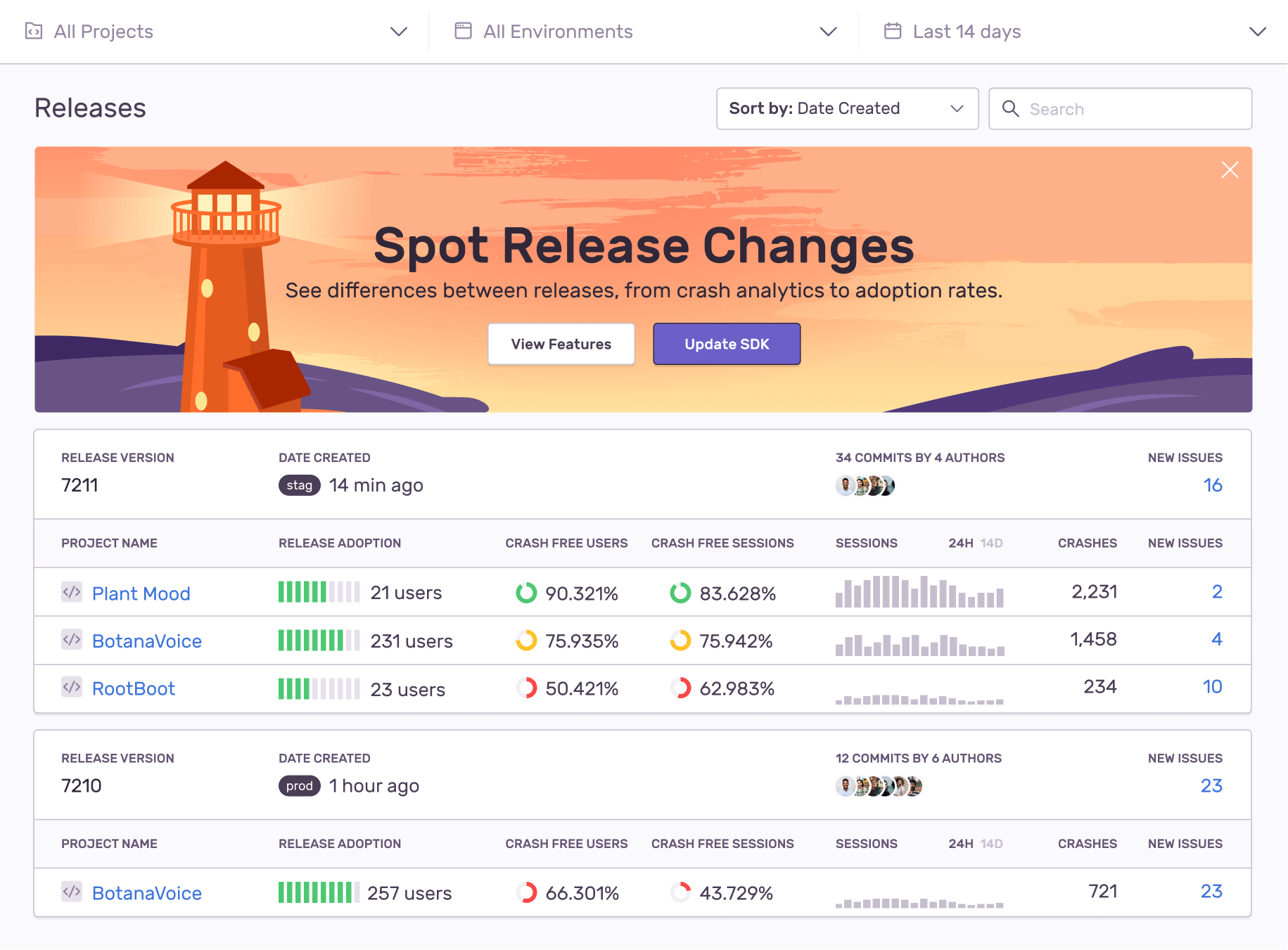
For example, on our releases page we fetch everything from sessions, users, version adoption, crash count and histograms. But if we fetched everything at once, there’d be the data equivalent of a traffic jam — and it would take some time before users would be able to see their data.
Which is why we split it into two parallel requests. By showing the results immediately after the first request finishes — instead of showing a spinner — users now don’t have to wait for all data to render just to see some of their data.
Even though these data sets are fetched in parallel, we noticed in Performance, how the gap between those two phases initializing can be substantial. What’s more, we found this time gap to be even more pronounced for release-heavy organizations who push code multiple times per hour.
From a UI perspective, the default choice would be to toss out one of those loading spinners while the lagging data set was still rendering. But we felt that wouldn’t be fair to the data — or our customers. So we decided to introduce two-phased loading, in which we fetch releases and health data separately — while still in parallel. The result? A 22% faster UI, with almost half a second saved in load time.

There’s no use in producing error data if we can’t present that data to our customers. It’s why, in using Performance to improve Release Health, we’re finding new ways to scale to the demands of large-scale enterprises. Even so, we can’t miss the forest for the trees. Because if an error occurs in a forest of data with no one to see it, the sound it makes is your users leaving.


