Yes, Sentry has an MCP Server (...and it’s pretty good)
Yes, Sentry has an MCP Server (...and it’s pretty good)


Unless you’ve been living under a rock, “MCP” is probably a term you’ve heard thrown around in the AI space. Each of the editors and LLM providers have been racing to add and enhance their MCP support. Sentry was fortunate enough to be included in Anthropics release announcements for MCP. VS Code and GitHub Copilot recently expanded their MCP options, Cursor just released their 1.0 (congratulations 🎉!) which added a lot of love to their MCP, like support for OAuth directly, Streamable HTTP support, and more. Windsurf continues to grow their support for MCP in Cascade, even Raycast jumped on board and added MCP support.
MCP, or Model Context Protocol, is an open protocol designed to standardize the way context is brought into LLM interactions. We’ll unpack this more later in the post, but jumping ahead - yes, as the title of this post suggests - Sentry has an MCP server. You can learn more about it by visiting the MCP server address directly, or in our product docs.
The Sentry MCP has support for all the newest fun bells and whistles, including:
Remote hosted (preferred) or local STDIO mode (we strongly recommend the hosted version. It’s lower friction and you’ll always have the latest functionality/stability)
OAuth support to enable logging in via your existing Sentry organization, so you’ll have clear access to your organization and projects
Streamable HTTP with graceful fallback to SSE if your client doesn’t support it
16 different tool calls, including prompts, to support bringing wide context in from Sentry, including tools like project information, issues, finding or creating projects and DSNs, and even calling our AI agent Seer to generate root causes and fix issues (see the full list here)
The Sentry MCP can be added to most providers that support OAuth by adding the following content to your MCP Configuration file:
{
"mcpServers": {
"Sentry": {
"url": "https://mcp.sentry.dev/mcp"
}
}
}For clients that don’t support OAuth, you can continue to use the existing Remote MCP endpoint configuration. If your client doesn’t support Streamable HTTP yet, this will automatically fallback to the SSE connection.
{
"mcpServers": {
"sentry": {
"command": "npx",
"args": [
"-y",
"mcp-remote@latest",
"https://mcp.sentry.dev/mcp"
]
}
}
}With these in place, you’ll be prompted to accept OAuth and you should see the tools become available.

OK… but why a Sentry MCP?
As you might imagine, when applications go sideways, the context of where that broken code is at, or where/how performance issues are happening, matters a lot. Using MCP as a bridge to give users access to that context from within the LLM is clearly a good way to enable getting that.
When we started building the Sentry MCP server we had some really specific requirements that we cared a lot about.
Make it as low friction as possible to consume as a service
The typical “local” approach to MCPs (using STDIO) works fine for advanced users, but cloning the repo, setting up the configurations, remembering where the file path is, and continuing to keep it updated is a lot of sharp edges
Making people create API tokens and pass them around is… not great. Support for OAuth was necessary, and let’s treat it like another application connection coming into Sentry. We don’t need to reinvent the wheel
Because of Sentry’s scale, if we were going to host it somewhere, we needed to be able to handle significant user load
We knew early on that our MCP was going to need to be a hosted / remote solution. Cloudflare has been building out a lot of tooling to make getting Remote MCPs up and running at production scale, quickly, pretty easy:
Their OAuth provider library let us quickly bolt on Sentry’s authentication providers
Durable Objects provided persistent, stateful storage between user sessions
Cloudflare workers gave us the scale of the global edge network, and an easy deployment target to run the workload on (alongside the previously mentioned tooling)
This combination gave us a quick path to getting the service out in the wild for users to consume, while also giving us enough flexibility to keep building functionality on top of it.
Also, as part of this work, we were able to add specific support for MCP to our JavaScript SDKs, which gives a lot more visibility to the underlying functionality of the protocol and tool calls. David Cramer wrote about instrumenting an MCP server in production with Sentry, and it digs into everything from monitoring the core MCP functionality to monitoring the Durable Object layer as well.
Why context matters
Without some way of bringing in extra context, the models are forced to rely on only the content they’ve been trained on - which often ends up being out of date (remember that time you tried to have an LLM setup Sentry and it installed that weirdly ancient version of the React SDK?). This happens for a lot of reasons that we won’t cover entirely in this blog, but the short version is a mix of 1) amount of that version (for example) appearing in the training data and 2) the actual versions at the time of the training date.
In “normal speak” - you can use MCP tool calls to bring in clearer information for the LLM to use in its responses. In practice, this ends up looking a lot like a set of APIs that can be used to retrieve this information. Lets check out an example of an MCP tool -
const server = new MCPServer({
name: "Sentry".
version: "1.0.0"
})
server.tool(
"list_projects",
"This call finds all the projects that are available to a user's organization in Sentry"
{
organization_slug: z
.string()
.describe("The slug of the organization to list projects from")
},
async ({
organization_slug
}: {
organization_slug: string
}) => {
const apiUrl: string = `https://sentry.io/api/0/organizations/${organization_slug}/projects/`
// fetch call to get results, parse them out, dump them into a response
return response
}This tool call has..
A name for the tool -
list_projectsA description of the tool that the LLM will use to understand when this tool is useful - “This call finds all…”
Expected input parameters to the tool -
organization_slugA function that actually gets the context, formats it, and returns the information back to the LLM.
Without MCP, the LLM would have no knowledge available on what projects were available for the user. MCP ends up becoming that bridge, and using the example above, the LLM now has a tool it can use (list_projects) to access that context and use it in future calls or responses..
You might initially think that there’s very little use in getting project information like the above call; but often these tool calls are chained together. Running Seer’s Issue Fix against a bug that appeared actually requires several tool calls to get the right context together to actually kick off the API call.
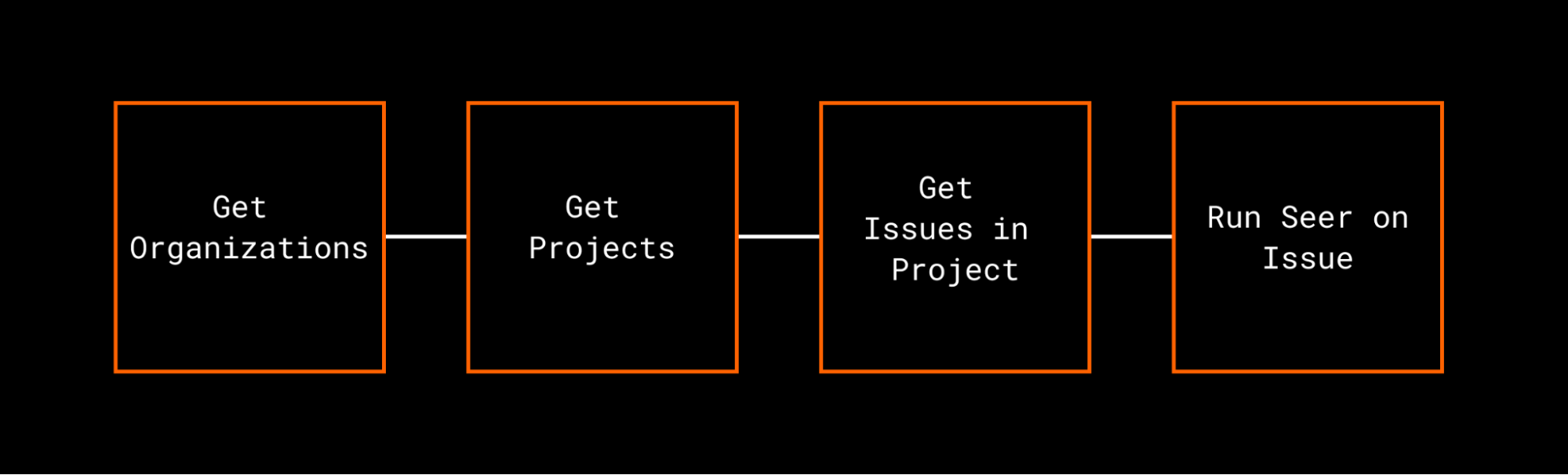
Because MCP is designed to pull this kind of context in, it’s able to look at the tool descriptions and the tool schema to determine which tools it can use to fulfill the requirements. It can then chain the different tool calls together to kick off Seer’s analysis run, and return the RCA when it’s ready.
The editors will often store certain parts of these tool results in their own context (or memories) to use in future calls. For example, my organization is 'buildwithcode' and my editors have stored knowledge to use that as my default organization. This saves on token usage in future calls, because these tools won’t always need to be run again.
These tools are also useful when you start to expand beyond just the core product workflow, and into chaining tool calls between different platforms, for example, calling a Linear issue from within your IDE and having that Linear issue information also lead to calling issue details directly from the Sentry MCP as well.
MCP ends up becoming a stitching layer for bringing context across multiple different platforms together in your LLM - so the LLM doesn't assume (aka hallucinate) context on its own.
Should I use Sentry MCP or Seer?
You’ve probably heard us talk quite a bit about Seer recently, our AI Agent that’s being released to help scan issues, understand root cause of bugs, and propose fixes for them. We’ve heard a lot of questions around if the Sentry MCP or Seer should be used to debug and fix issues.
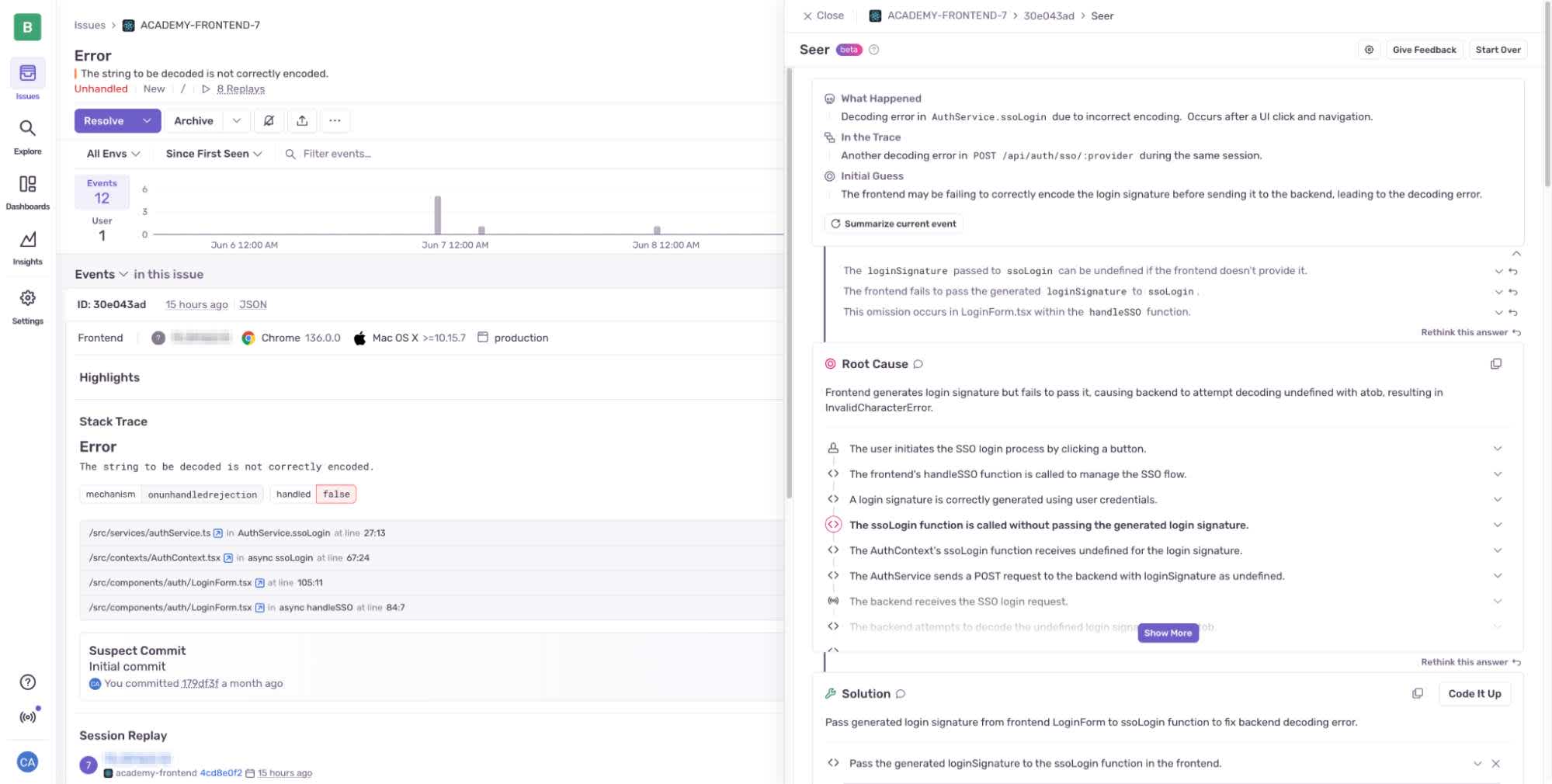
We see these tools as complimentary to each other. It’s important to point out that MCP in general is not built for debugging - it’s built for bringing context into your LLM from external sources.
Seer is purpose-built for understanding why your applications are breaking, and how you can get them fixed. Think “deep research” but specifically for bugs and performance issues in your applications.
Trying to accomplish the same thing using MCP would result in you manually stitching together many different tool calls, and trying to graph out the relationship between them. It’s not going to be easy.
Meanwhile, the MCP can (as we discussed earlier) make calls to Seer to kick off the issue fix operations. At the end of the day, they are different tools for different problems, in a similar space.
Where do we go from here?
MCP certainly has its share of sharp edges and challenges associated with it. Being declarative on which tool calls to use, controlling pathing between different till chaining, and even parts of authentication still have their share of bugs.
That said, MCP is still in its earliest days, and has made a ton of progress in a short period of time. We’ve already seen the protocol grow in popularity and functionality, and it’s clearly not going away anytime soon.
On the Sentry side of things, we want to learn more about the workflows that you’re looking to accomplish using MCP. We’re looking at everything from initial instrumentation all the way through issue research and automated resolution. We want everyone to take the Sentry MCP for a spin in whatever client makes the most sense for you, and let us know how we can make it more useful.
If you run into any issues, drop a note in the GitHub for the project. Happy building!



