The Sentry Workflow — Resolve
The Sentry Workflow — Resolve

*Errors suck. And you don’t want to spend too much of your time fixing them, dealing with them, investigating them, etc. In our Workflow blog post series, we look at how to optimize your, well, workflow, from crash to resolution. *
At this point in our workflow (check out the first and second posts in this series), we’ve minimized the impact of errors on the development process by creating infrastructure and culture equipped to handle unexpected issues. So far so good — now we have visibility into our code that allows a more holistic picture of the entire service.
But, as you can surely guess from the topic of this post, our workflow is not yet complete. In this post, we’re wrapping up this Workflow series with a look into resolving issues with ease so that you can start the next round of your workflow (editor's note: how many times do you think we'll say the word workflow in this post?) with a clean slate.
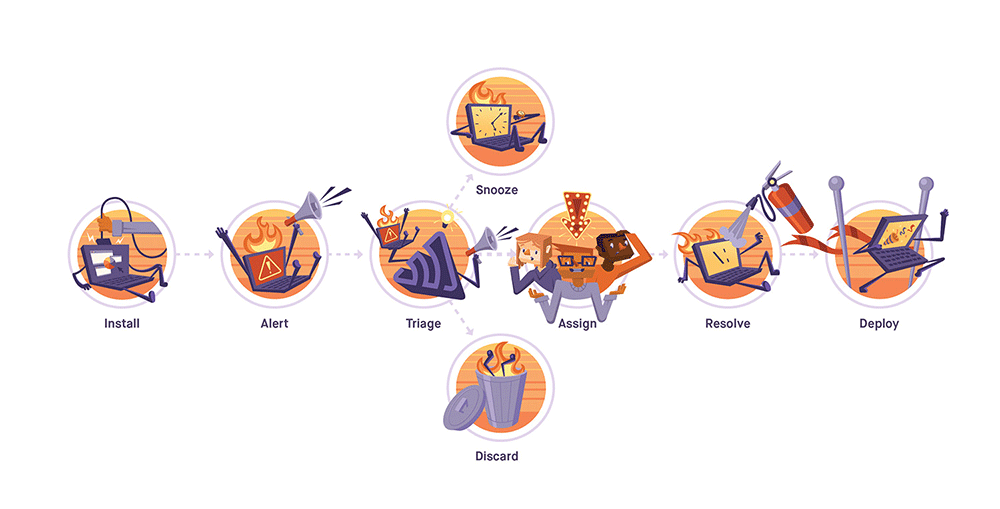
Resolving issues
In our last post, we began the Triage phase of our workflow by uncovering the who, what, when, where, and why of the issue and ended by using the commits integrations and features with source code management providers to assign the issue to the appropriate owner.
Now that the newly assigned issue owner has the context to iterate on the code and commit the fix, resolve via commit is a useful way for that engineer to stay organized and productive by never leading their text editor. Referencing the issue in the commit (e.g., Fixes ISSUE-ID-123) will mark it to resolve in that specific release and mute notifications for that issue before the fix deploys.
Issues can also be marked ‘resolved’ in a future release. Because it’s unnecessary to actually go into Sentry and manually mark the issue ‘resolved’, developers can focus on developing and/or fixing issues instead of tracking those issues. In other words, fix + RVC, push your code up, and move on.
Resolving issues in future releases also means that errors coming in from old releases won’t trigger alerts, which helps keep noise to a minimum. If an error occurs in the release (or version) that was supposed to contain the fix, a regression notification will be received.
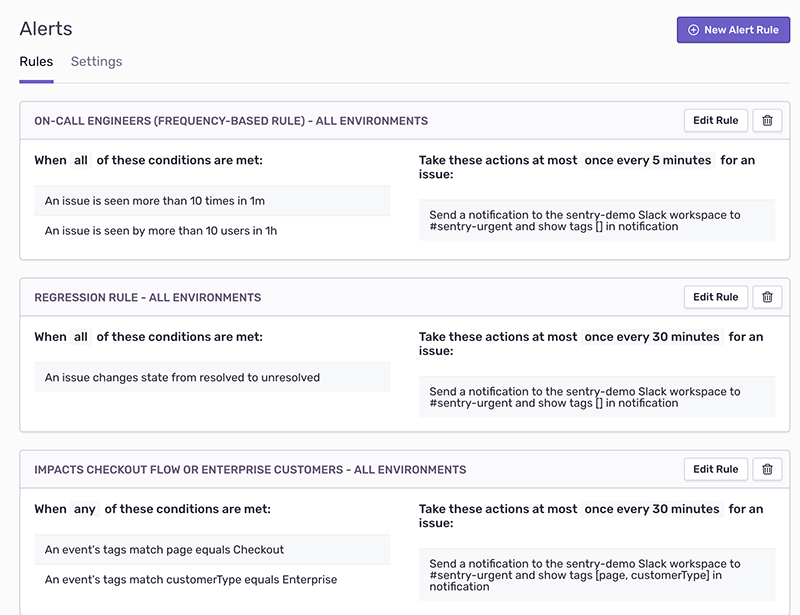
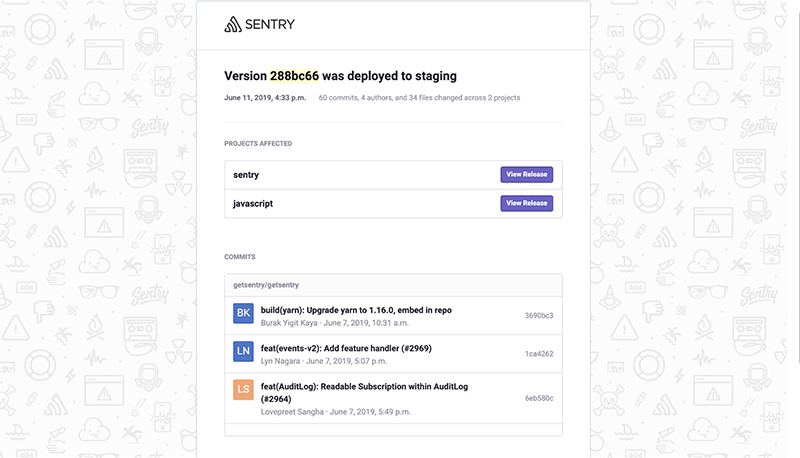
Deploy emails
The deployment pipeline then picks up the change and deploys it. Unfortunately, it’s often difficult to know when code or code changes actually made it into production — this can result in time spent investigating various systems and eventually testing to see the status of that code or change.
Deploy emails can be configured to send details on how many files have changed and what commits are being released once the code gets deployed.
Congratulations, now we’re done. You’ve just made iteration a seamless part of your existing development workflow. When done right, fixing bugs becomes a fluid part of the development process.
If you have any questions, be sure to reach out to our support engineers. They’re here to help. And also to code. But mostly to help.


