Rethinking Sentry's Documentation
Rethinking Sentry's Documentation

If you have searched for the Sentry or integration docs lately you might have
noticed that some things have changed. There are now consolidated docs for
Sentry and the raven clients right at docs.sentry.io:
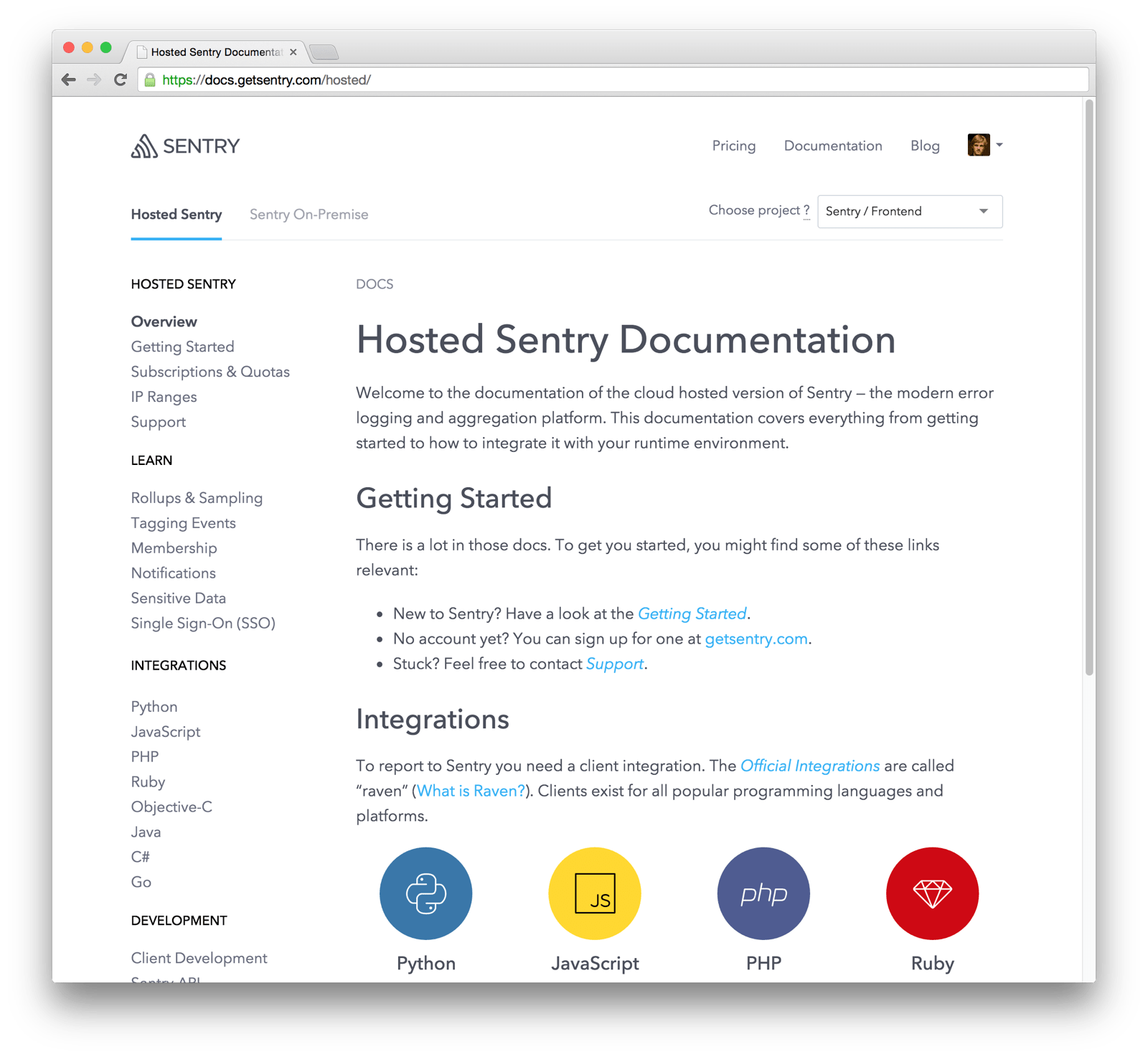
This not only improves the ease with which you can get started error monitoring with Sentry, but also improve your bug tracking workflow with docs about integrating Sentry's with other tools in your stack.
Evolving Documentation
Because of Sentry's and the Raven clients' root as a collection of Open Source
projects, documentation was so far something that was bundled with the clients
or the Sentry server. This lead to the situation that as a user it could be
quite challenging to find all the relevant information as it was scattered
around the place.
We finally wanted to tackle that problem and unite all the documentation in a
central place. However, we also wanted to stay true to where we come from and
make sure that the documentation for the individual components can be built
separately. In addition to that, we wanted to be able to tag off the state of
the documentation with Sentry releases and ship it out with the server
tarballs.
Another slight complication was our requirement have two variants of the
documentation for the cloud hosted version and the on-premise / Open Source
edition of Sentry. While they are largely the same, there are some specifics
that make it easier to treat them as separate projects.
Picking Technologies
Most of Sentry used the Sphinx documentation tool to build the documentation
but some parts were just readme files in github repositories or the github
wikis.
So we knew roughly what we wanted, but early experiments with Sphinx showed
that it's not entirely up for the task. We had problems getting the navigation
to work the way we wanted and some of the design decisions in it made it very
tricky to build composable docs. Unfortunately, looking around for alternatives
it did not look like there were any tools around that were a better match for
the task.
So we gave Sphinx another shot by extending it. While Sphinx suffers from a
quite a few design missteps that made extension in the ways we needed very
challenging, we managed to achieve our goal in the end by making some
sacrifices.
Compared to stock Sphinx we lost the ability to generate PDF documentation and
we can no longer build just the files that changed but need to rebuild the
documentation from scratch. These are both two areas that would be nice to
improve but will require some deeper changes in Sphinx itself.
The Components
So how does it work? The end result is structured in a range of different
parts that all need to work together.
git: We heavily depend on the individual components being maintained as git
repositories. The reason for this is that we want to treat the entire
documentation in the end as a cohesive product, so we use git submodules to
merge them together. We keep the documentation in the individual projects as a
sub directory. The repos are then referenced as submodules in a master
sentry-docs repository.
a push hook: Now that every piece of component has a repo and a
documentation folder, we use a push hook to sync the referenced submodules to
exactly the version we want. We do this rather than tracking a branch on the
submodules so that we can tag off individual versions of the documentation with
git releases.
a Sphinx extension: Another very important part is a Sphinx extension that
adds custom support for the things we need. It's referenced by a submodule
from every single component so that the documentation can be built seperately.
This extension we will go into detail a bit later.
A Simple Workflow
For the documentation author the process is quite simple. No matter which
component you modify, the hook will automatically update the master sentry-docs
repository and make a commit. Pushing updates to the production website then happens via our deployment tool, Freight. While currently a manual process we will be expanding the project in the future to automate all releases for docs.

Documentation Variants
It was very important for us to have at least two variants of the documentation
for the on-premise and hosted edition of Sentry. We also have a third internal
variant called the "self" variant which is used whenever a component's own
version of the documentation is built.
As Sphinx does not have a concept for this and it works against how it
structures it's internal "toctrees" (A tree of document and headline
relationships), we had to solve this through a process of preprocessing.
We hook the preprocessing step of Sphinx to hide and show individual sub
segments of the document. To give you an idea how this looks like you can
have a look at the raw source of the quickstart
document. The sentry:edition directive looks like any other reStructuredText
directive, but is in an actual fact a preprocessing instruction that is resolved
with some regular expression hackery. Because the syntax is heavily line and
indentation based, we could implement this in a way where it feels and behaves
exactly like any other rst directive.
To give you an example of how these directives work, take this basic example
from the quickstart:
.. sentry:edition:: hosted
1. `Sign up for an account <https://sentry.io/signup/>`_
2. :ref:`pick-a-client-integration`
3. :ref:`configure-the-dsn`
.. sentry:edition:: on-premise
1. :ref:`install-the-server`
2. :ref:`pick-a-client-integration`
3. :ref:`configure-the-dsn`In addition, we had to replace the default HTML builders with builders that
do not emit unreferenced documents. This allows us to just affect the
final build artifact purely through the sentry:edition directives. If
a document ends up unreferenced in a certain variant, it's skipped for the
final result.
Customizing the Sidebar

A lot of work went into the sidebar of the documentation. This looks like
something that should not be that hard to achieve, but sadly due to
how Sphinx ix structured, it required a significant amount of work. As
mentioned before, Sphinx uses the concept of "toctrees" to structure the
entire documentation. This tree gets merged and processed in one monolithic
function within Sphinx and is also used to generate the navigation bars
and local table of contents. We had to write a replacement for this in
our Sphinx extension.
In our extension we take merge the toctrees like in Sphinx itself, but we split
them up into subsection based on selectors. This allows us to have a split
sidebar that otherwise functions exactly as you expect.
We extensively use hidden toctrees to structure the page how we want. Most
of the index page is empty with the exception of the client list, but it
also contains a hidden tree of documents that should appear. The sidebar
then picks up on these and renders it.
Dynamic Elements
It was important for us that the documentation ends up in static HTML
files that can be served up from anything. This has two benefits: it
makes it easy and reliable to host, but it also allows us to ship the
very same docs to customers and it works. However we still wanted to
have some dynamic elements in the documentation.
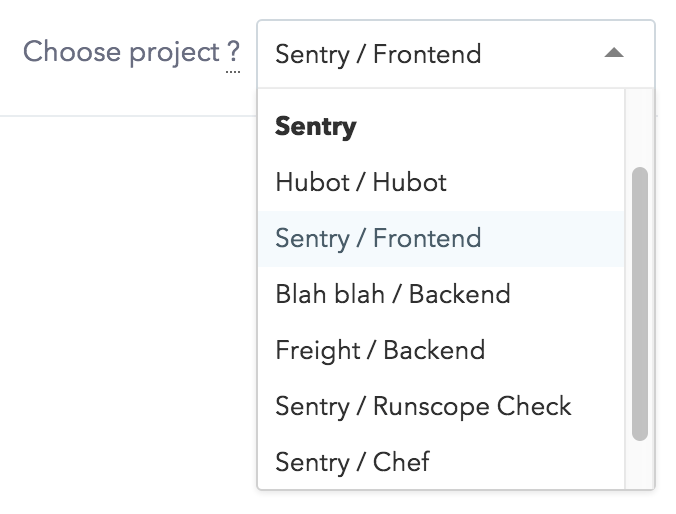
Two parts are notable: we want the header to reflect the authentication
status for getsentry customers and we want code examples to contain the
correct authentication keys so that copy/paste becomes possible.
For this to work we perform a cross domain request to a specific API
endpoint on getsentry which provides the information to render the
correct header and API key information. To avoid visual problems with
the header loading in a deferred way, we intercept all page navigation
and replace them with dynamic loading. For that we perform an AJAX
request to load the page content, parse the DOM to extract the areas
we want to replace, and then perform a DOM swap of those elements.
Lastly we scan over all code blocks to replace our DSN (API Key)
markers with the value selected from the API key dropdown.
User Experience
Lastly for the design of the whole end product we use a combination of
jQuery and Less managed through webpack and some traditional Jinja2
templates. For styling individual elements in the documentation we
take advantage of the ability to assign CSS classes through the class
directive in reStructuredText.
Additionally we wanted to ensure that the dynamic elements of the page
didn't cause a serious impact to the end user. To do this we implemented
a basic layer on top of browser history API. We hook
all anchor tags which link to the same domain and load updated content,
both for the sidebar and main body.
Wizards
Another benefit of the documentation we have now is that we can define
wizards through section selectors. This allows use to mark certain
parts of the documentation relevant for a wizard that should be
embedded in Sentry. In the near future when you create a new project
in Sentry the application will guide you through setting up your
project by directly extracting that data from within the documentation.
The wizard configuration looks like this now:
{
"wizards": [
"python-flask": {
"name": "Flask",
"client_lib": "raven-python",
"is_framework": true,
"doc_link": "integrations/flask",
"snippets": [
"integrations/flask#installation",
"integrations/flask#setup"
]
}
]
}The snippets are a list of paths to the documents that define them
and the ID of the section (headline). This allows us to sub select
small parts of the overall document without having to maintain multiple
similar documents with the same content.
Big Picture
So where would you find all these bits and pieces if you chose to build
something like this yourself?
the overarching documentation repository with the design, the custom
JavaScript and makefiles can be found at
the Sphinx extension and a pre-commit hook for some sanity checks
exists at
getsentry/sentry-doc-supportthe push hook unfortunately is currently proprietary because it
has some secrets in the repository we did not split out yet. But
that part is not very interesting.for deploying we use our own freight.


