Introducing Dynamic Sampling
Introducing Dynamic Sampling


This content is out of date
Since this blog post has been published we’ve evolved the feature to reduce complexity of configuration and automatically store the most valuable transaction data for you. Please see our docs on Performance at Scale to see all the latest info.
In the monitoring industry there's a complicated and frustrating conversation that persisted over the years: how do you deal with the enormous volume of data generated by instrumentation? On one side of the aisle, you will find a cohort of vendors and developers telling you that you have to sample data, followed immediately by another group telling you that sampling will ruin the accuracy of incident analysis. They're both right.
Two weeks ago we kicked off a closed beta for our Dynamic Sampling (DS) initiative. For those not familiar, DS is an enabling technology that allows us to push sampling decisions to our edge platform via Relay, allowing semi-realtime changes to sampling heuristics. This is designed to replace - or at least supplement - what is often a static configuration within application deployments. It's also a technology we're building into the core of how we do business at Sentry, but our initial focus is on our performance monitoring telemetry.
Before we dive more into this, a shout out to all of our customers who are helping us kick the tires on this. If you're not already on the list and interested, sign up here.
Back to the topic at hand - Dynamic Sampling - and why we believe it's the future of high-volume data analysis.
When Sentry was first designed we had a simplistic sampling heuristic that worked extraordinarily well for most customers. We'd take all of the errors you sent us, process them on the server, and throw away 99% of them. At the same time, we always ensured we had a reasonable sample size for every unique error. The logic behind it was pretty dumb simple: store every unique error, store the first 100 samples, and then store samples irregularly. This used a logarithmic scale meaning the more duplicates you had, the less we stored, and the cheaper it was to scale. While this was great, it isn't without its problems. The most obvious one is that if you're not indexing every single copy of an error, how can you aggregate the high-level insights and segmentation information you might need?
We solved that by building aggregate indexes for things like tags and other critical information (e.g. operating system, server name). This meant we had the best of both worlds: a low total storage cost and very high value within it. Ultimately this model didn't survive, partially due to customer demand, complexity in indexing, and the overall cost to the infrastructure which managed it. A few years later we dropped sampling entirely and moved to a store-everything model, but with a focus on minimizing the costs. While this works, it's not a one-size-fits-all, and while it mostly scales with our customers' error telemetry, it would be unrealistic to take the same approach to performance data. Our performance telemetry, in our most conservative estimates, accounts for one thousand times more data than the stream of errors, and it's just as heavy in context data size. This presented a new problem, with the only possible solution being sampling.
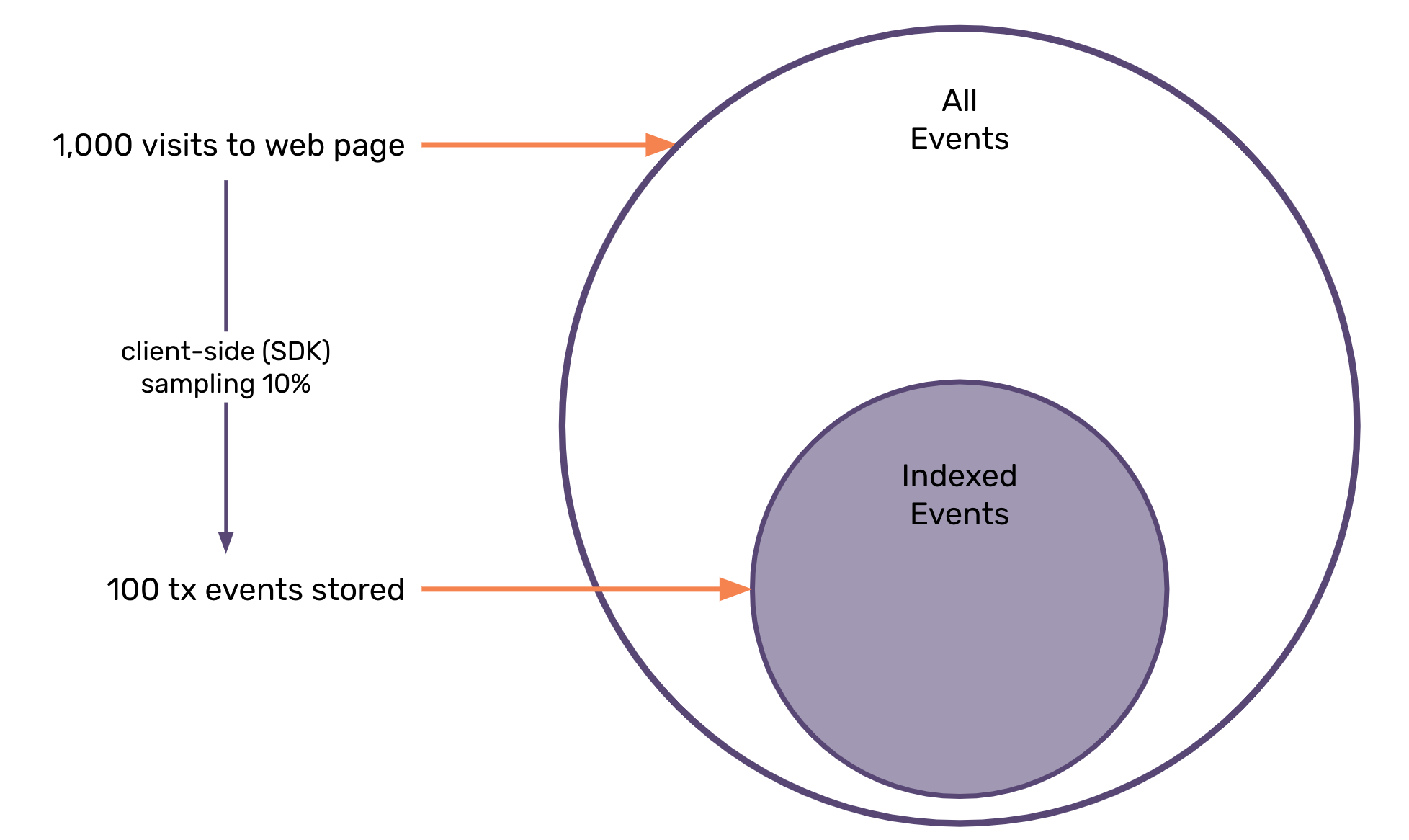
At first, we built a set of client-side sampling features for customers. In most cases, it’s a dumb sample_rate value that can be configured in our SDKs, but in some more advanced cases, customers will actually take an event-analysis-driven approach. This last part is critical, and the nature of client-side configuration means this is painfully difficult to optimize for most customers. Get your percentage too high? A painful bill from Sentry. Get it too low? Not enough data to get any value out of the product. Get it wrong? An application change is needed. In fact, for all of these, an application change is needed, and while that might seem easy to some of us, in many software stacks it’s very difficult to push out a new release.
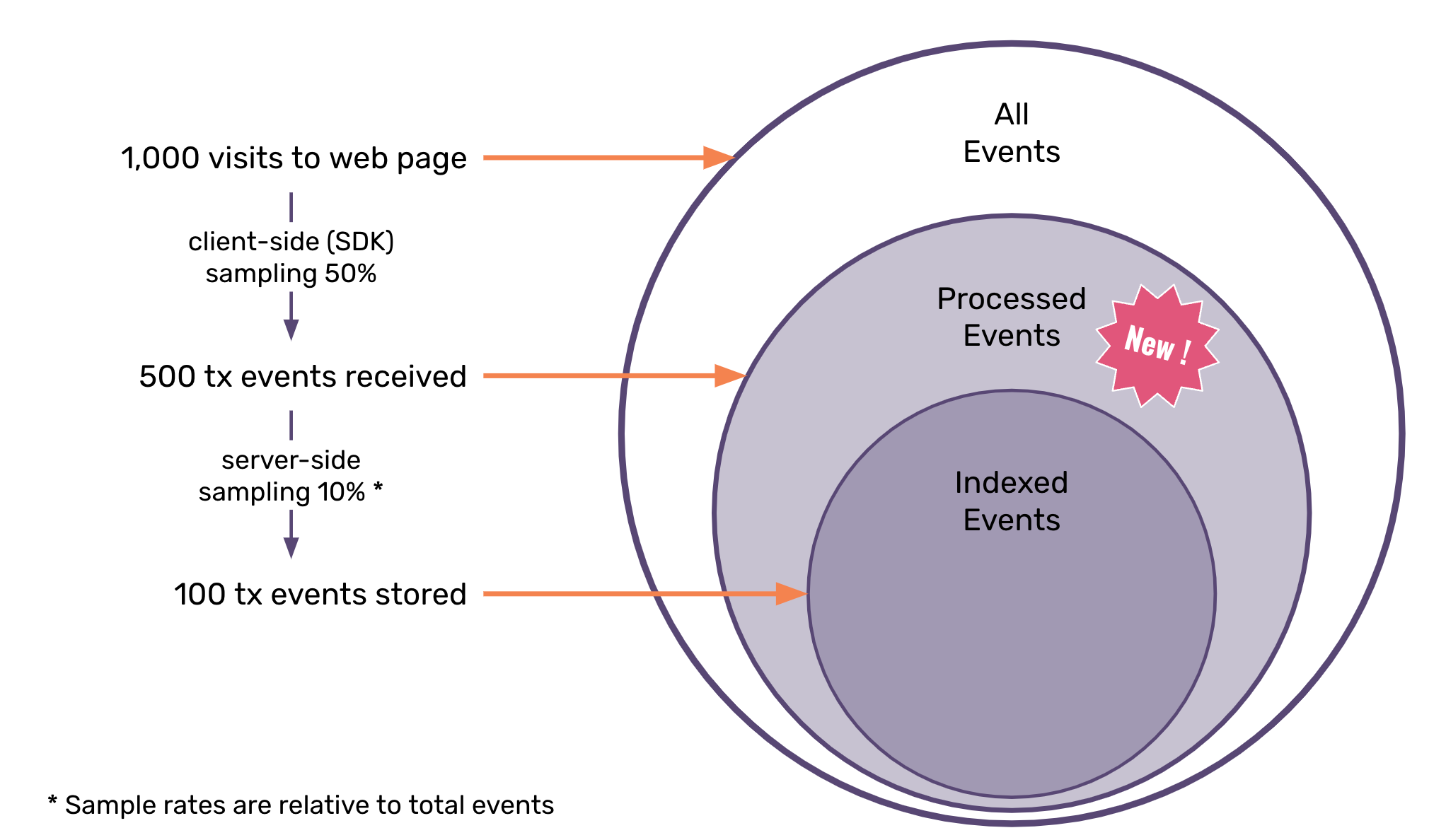
With Dynamic Sampling, we set out to rebuild our original approach to data volume scale. We kept a focus on maximizing value out of the data that is not only seen (we refer to as processed), but most importantly on the indexed events. To achieve this, we felt the best path forward was to build a technology that would allow us to continually evolve sampling heuristics, but also put many of those controls into the hands of our customers. After all, you know your application best, so who are we to tell you which endpoints and classes of customers are the most important?
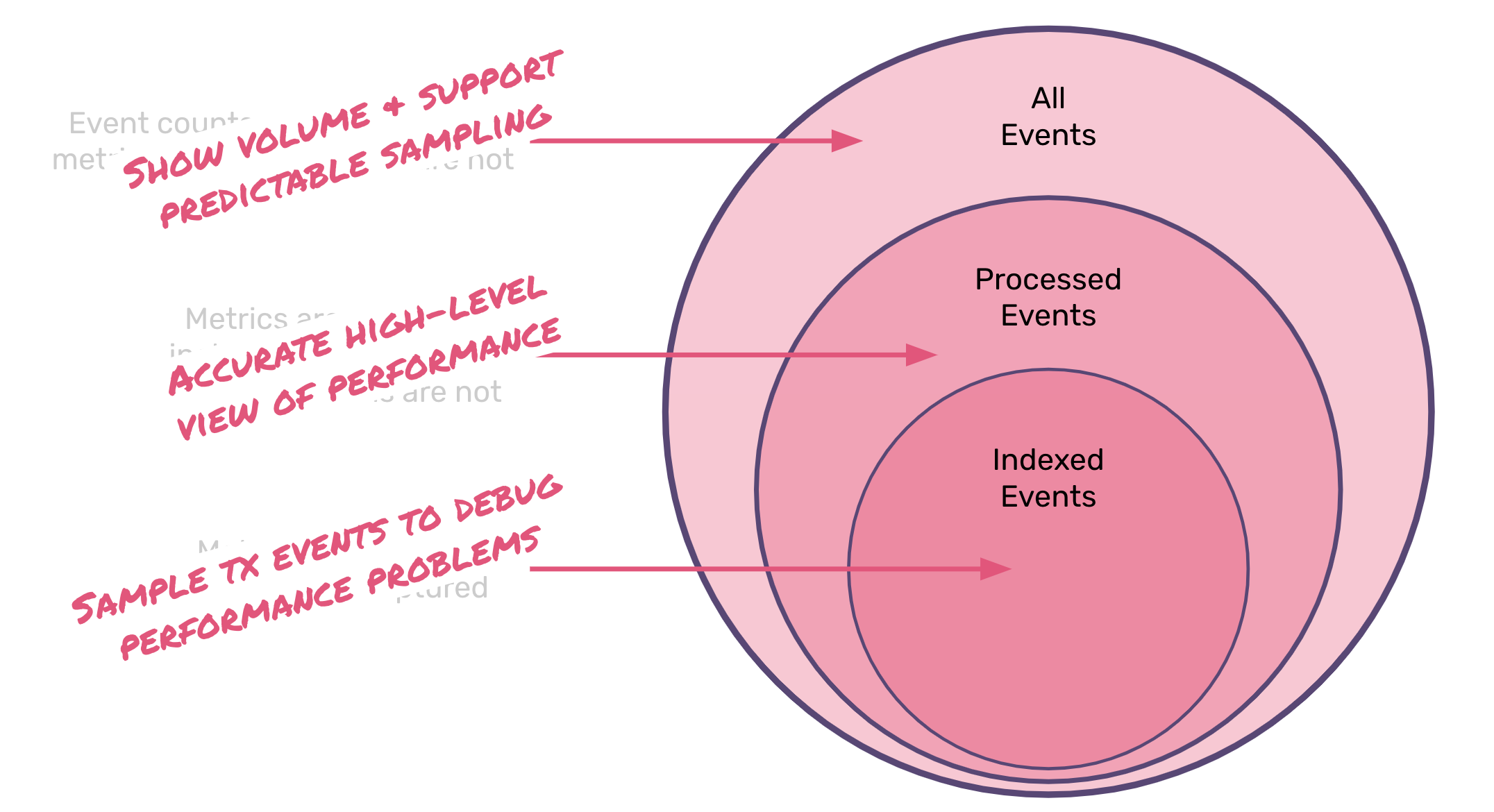
Building dynamic controls for sampling is arguably the easiest part of this new investment. The harder and more subjective nature of what we're doing is trying to extract value from everything you don't see. One of the biggest issues with client-side sampling is you have no visibility into the unknowns. This isn't Schrödinger's cat - just because you don't record a problem doesn't mean it didn't happen. That is the fundamental flaw with most sampling implementations - a lack of visibility into the unknowns. That's fairly difficult to solve for, however, so our approach is tackling this in two key ways:
We are providing high-level visibility (ala metrics) into core measurements with various dimensions pre-computed. This ensures you can always spot high-level problems and enables a capability to drill into related samples.
When we've failed to capture those samples, the dynamic nature of our approach means that you can quickly enable collection of targeted concerns, without any kind of application change (or most importantly, a new release).
At first, this means that you'll likely set pretty dumb sampling heuristics. That may be something like "10% of all transactions", but with an emphasis on more important endpoints. A great example at Sentry is we never want to lose any telemetry for our payment endpoints. Those are critical paths we need maximum coverage over. That will require a bit of manual work - telling Sentry where you want to dial up sampling - but the important piece of the puzzle is we let you do it. There's no magic, no secret algorithm, and no cryptic black box when it doesn't do what you expect.
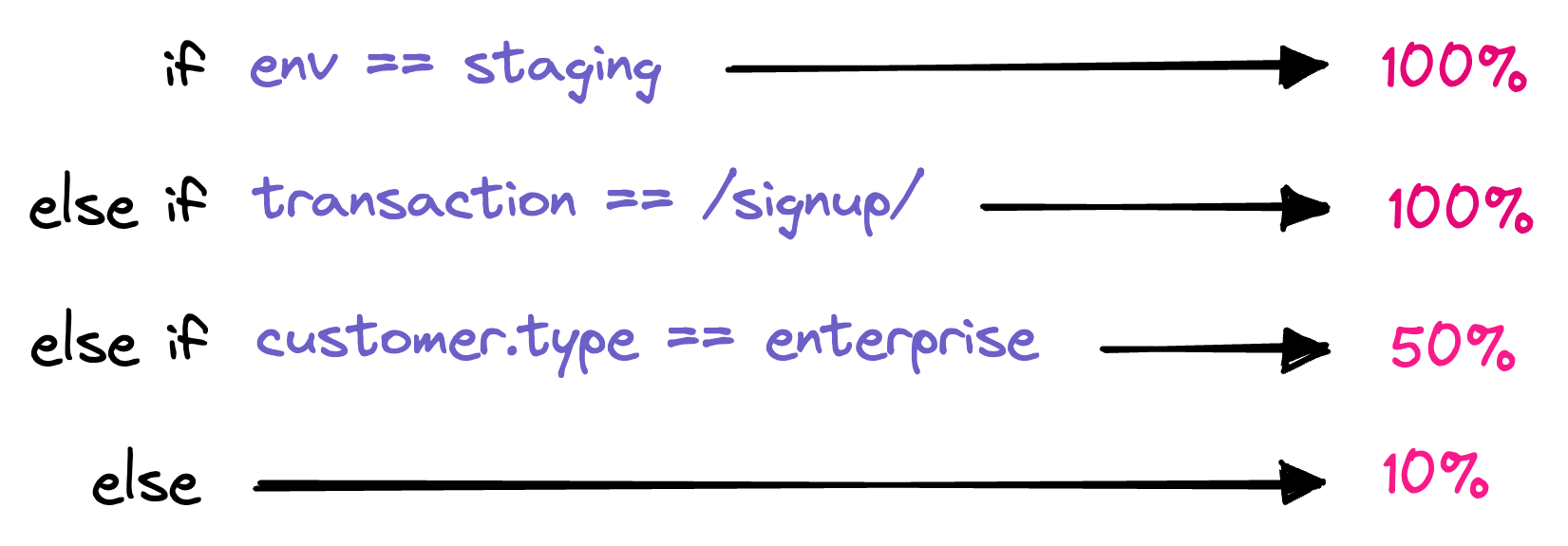
Over time our hope is we can find ways to enable even more intelligent controls around sampling. We still intend to make those transparent and optional, but we can teach machines to make faster decisions than we can as humans. As an example, when we bring this to Errors next year, we're thinking about how we can maximize the number of unique errors captured, while still intelligently sampling high-volume issues.
We'll be releasing Dynamic Sampling to all Sentry customers later this year as part of our Performance Monitoring offer. While it doesn't drastically change the product experience, we think it's a critical innovation that will enable us to bring this kind of instrumentation to every product, no matter the shape or size.


