Django Performance Improvements - Part 1: Database Optimizations
Django Performance Improvements - Part 1: Database Optimizations


The main goal of optimization in Django projects is to make it fast to perform database queries by ensuring that your projects run by making the best use of system resources. A properly optimized database will reduce the response time hence a better user experience.
In this 4 part series, you will learn how to optimize the different areas of your Django application.
This part will focus on optimizing the database for speed in Django applications.
Understanding queries
Understanding how querysets work will lead to better code. Before any optimization, start by understanding these concepts:
Querysets are lazy: you can write as many queries as you want, but Django will only query from the database when the query is evaluated.
Always limit the results you obtain from the database by specifying how many values should be returned.
In Django, you can evaluate your queryset by iteration, slicing, caching, and python methods such as len(), count(), e.t.c, so ensure that you make the best use of them.
Django performs caching in every queryset to minimize database access. Understanding how caching works will allow you to write better and more efficient code.
Only retrieve what you need
Retrieve everything at once if you think you will use it later
Always perform database work in the database rather than in Python
Query optimization
The database is the core of any application. Contrary to the belief, complexity doesn't always guarantee efficiency. Postgresql is the preferred database for Django applications due to its open-source nature; and it's also ideal for complex queries. To optimize queries in any Django application, we will cover the following areas to perform database optimization, namely:
database indexing
Caching
select related vs. fetch related
bulk method
RawSql
Foreign keys
1. Database indexing
Database indexing is a technique used to speed up querying when retrieving records from a database. When working with large databases that churn lots of data, indexing is a non-negotiable practice to make your app faster.
As the application becomes significant, it might slow down, and users will notice since it will take considerably longer to obtain the requested data. To illustrate this, we will use an example of an ecommerce store that has a table product with the models shown below.
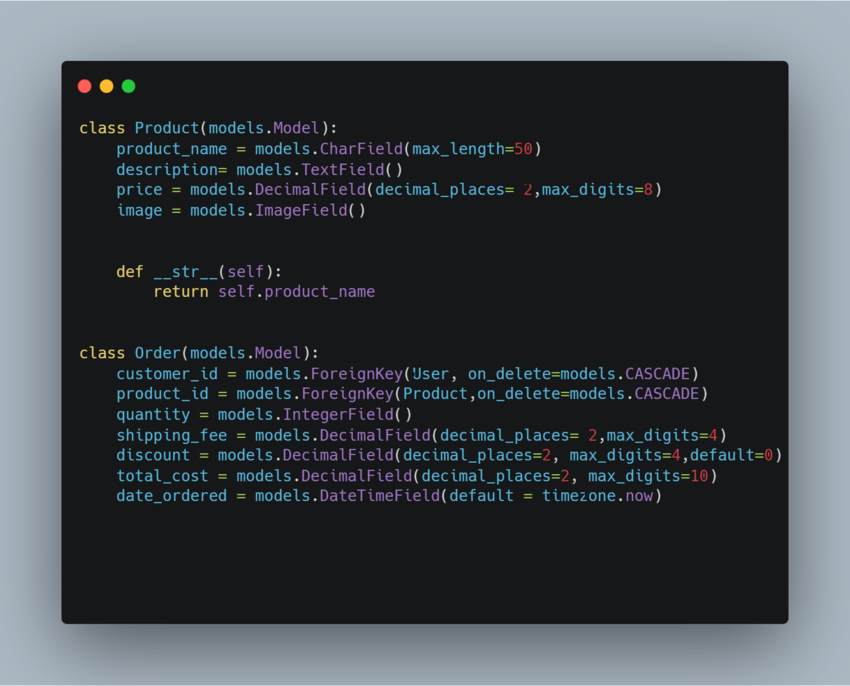
As the database grows, you might notice it takes a significant time to retrieve data. For example, assume you want to apply an index to the price column to speed up searches on the column.
price = models.DecimalField(decimal_places= 2,max_digits=8,db_index=True)After you apply the index, you will need to run migrations so that the index is created.
It’s also important to note that if the table has a lot of rows, it will take longer to create the index. You can also create a single index for two fields:
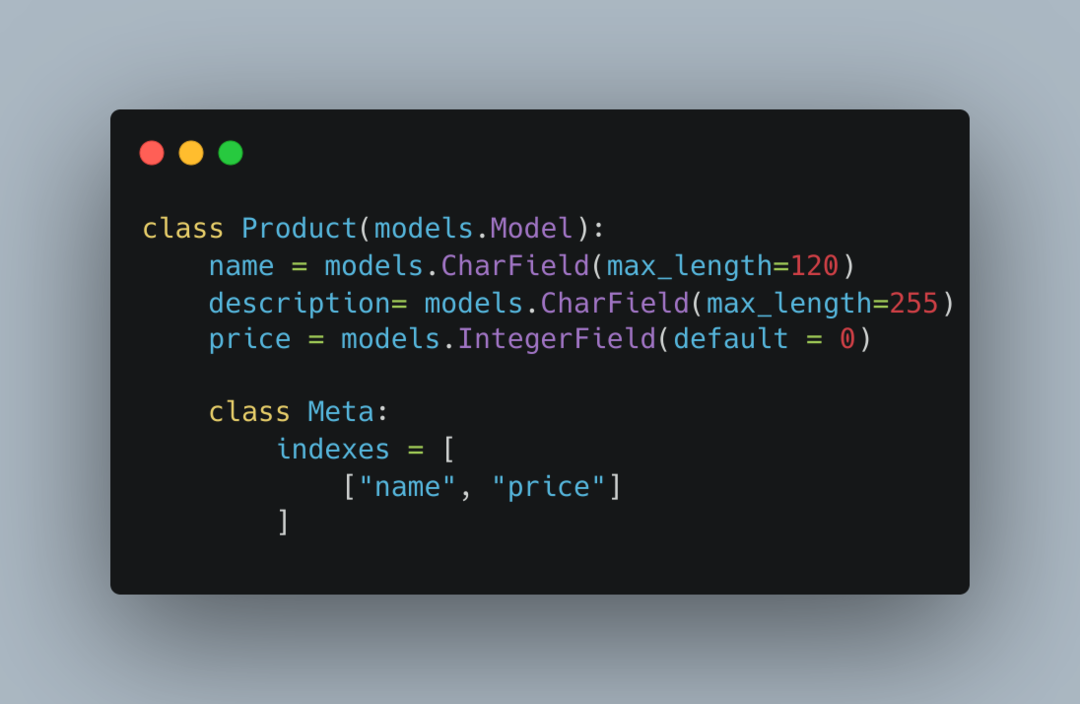
2. Caching
Caching in databases is the best approach to fast responses. It ensures that few calls are made to the database, preventing database overload. A standard cache structure will look like this:
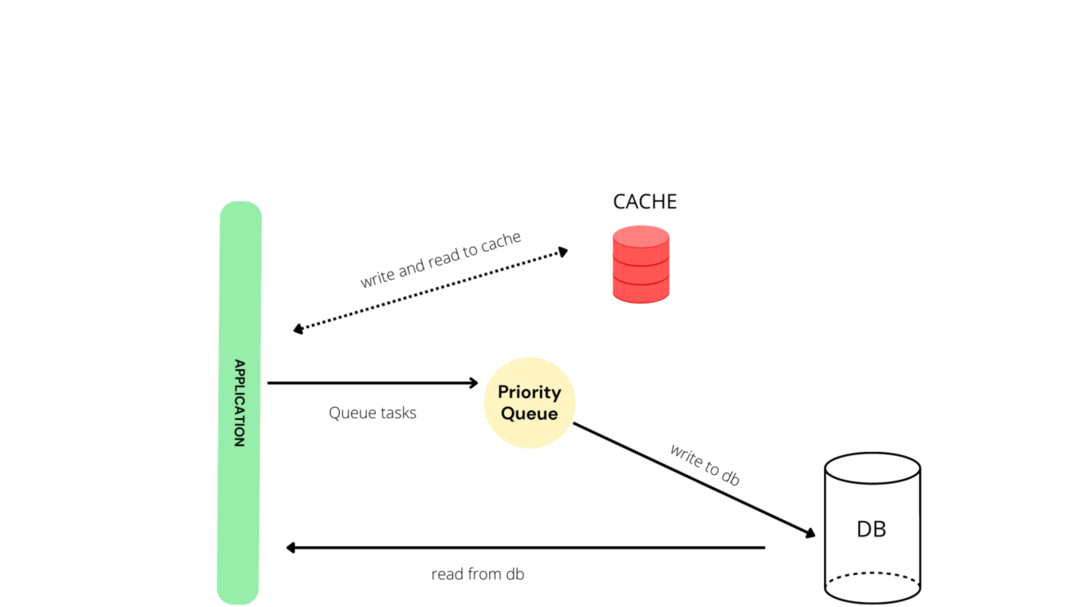
Django provides one caching mechanism that can use different caching backends like Memcached and Redis that allow you to avoid running queries multiple times.
Memcached is a simple yet powerful open-source in-memory system that is guaranteed to return cached results in less than a millisecond. Memcached is also easy to use and scalable.
On the other hand, Redis is also an open-source caching system that offers the same capabilities as Memcached. Most offline applications use already cached data, which means that most of the requests do not even hit the database.
User sessions should be stored in a cache in your Django application, and since redis persists data in disks, all the sessions for logged-in users don't come from the database but the cache. To enable redis database caching, you need to install redis via pip.
pip install redisOnce redis is installed, add the following code in the settings.py file:

You can also use Memcached and redis to store user authentication tokens. Since every user who logs in must provide a token, all these operations can result in high overhead on the database. Getting tokens from the cache will lead to a much faster-performing database.
3. Select related Vs. Prefetch related
Django offers parameters for optimising your Querysest called select related and prefetch_related. These two methods reduce the number of queries done on the database. For example, consider the following model with 2 tables.
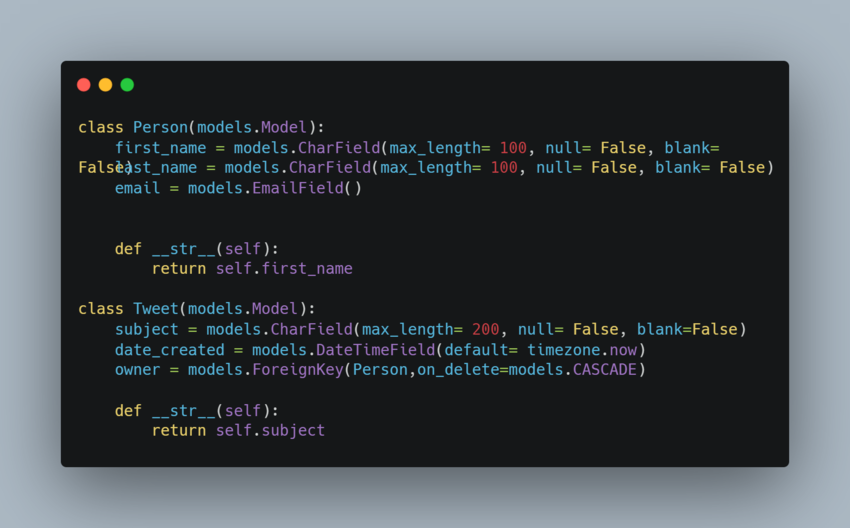
The person table has one-many relationships with the Tweet table, i.e., One person can have many tweets, but a tweet can only belong to a single person.
Suppose you want to find out the details of all the tweets in your database,you would first fetch all the tweets. To get additional information such as first_names and last_name you would then do additional queries as follows:
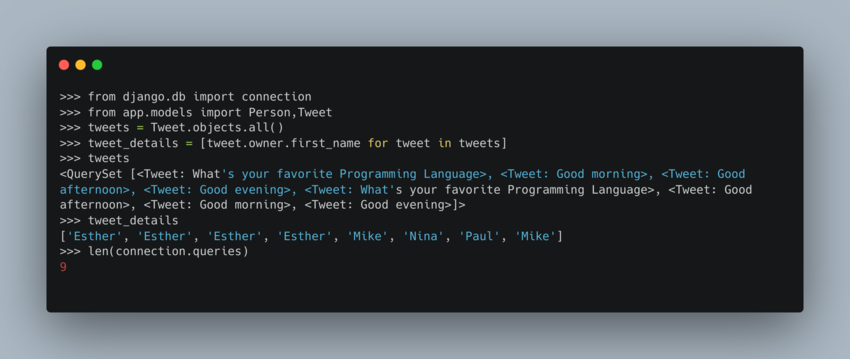
This results to 9 queries as shown above.
select_related
With select_related, you can make a single query that returns all the related objects for one-many and one-to-one relationships for a single instance. select_related is a query used on foreign-key relationships to retrieve any additional related-object data when the query is executed.
Though select_related results in a more complex query, the data obtained is cached; hence manipulation of the data obtained will not require any additional database queries.
Let's perform the same query with select_related.
queryset = Tweet.objects.select_related('owner').all()The code above will get all the tweets and person data all at once, resulting in only a single query.
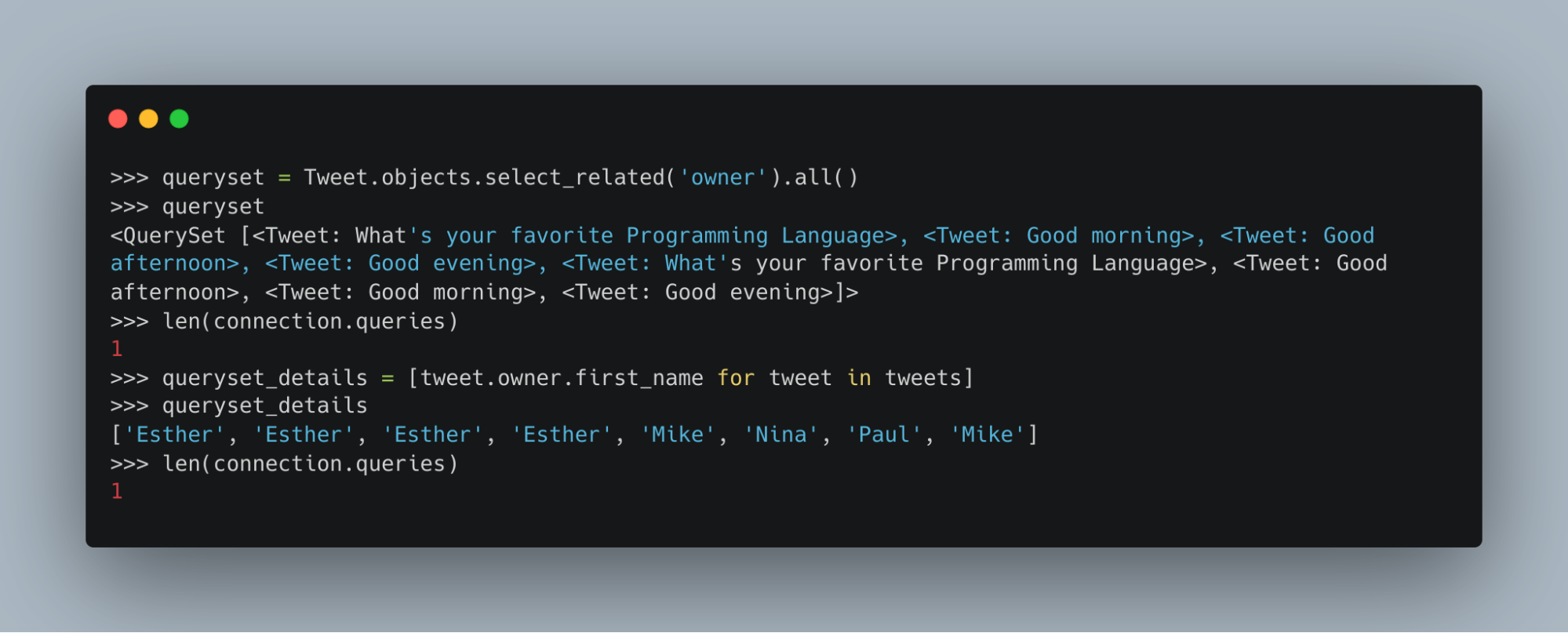
prefetch_related
prefetch_related, on the other hand, is used on many-to-many and many-to-one relationships. It results in one single query for all the models and filters specified in the query.
For example, suppose you have the following models:
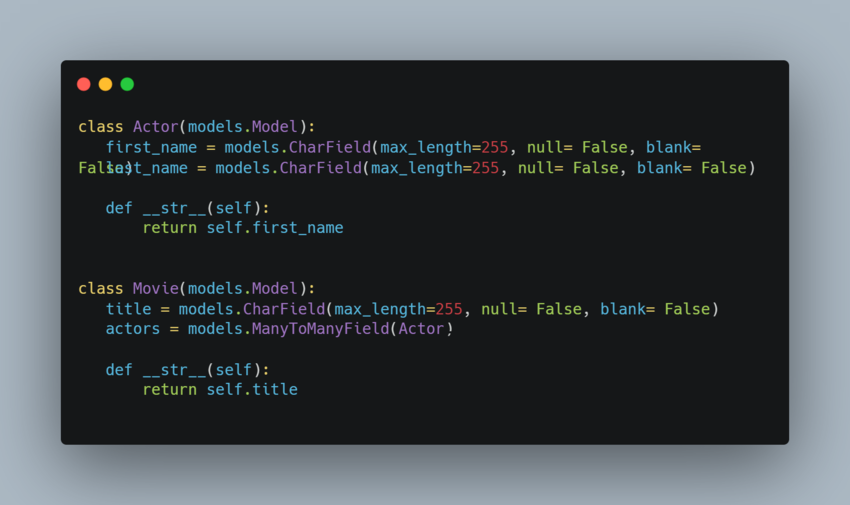
Lets fetch all the movies and related actors:
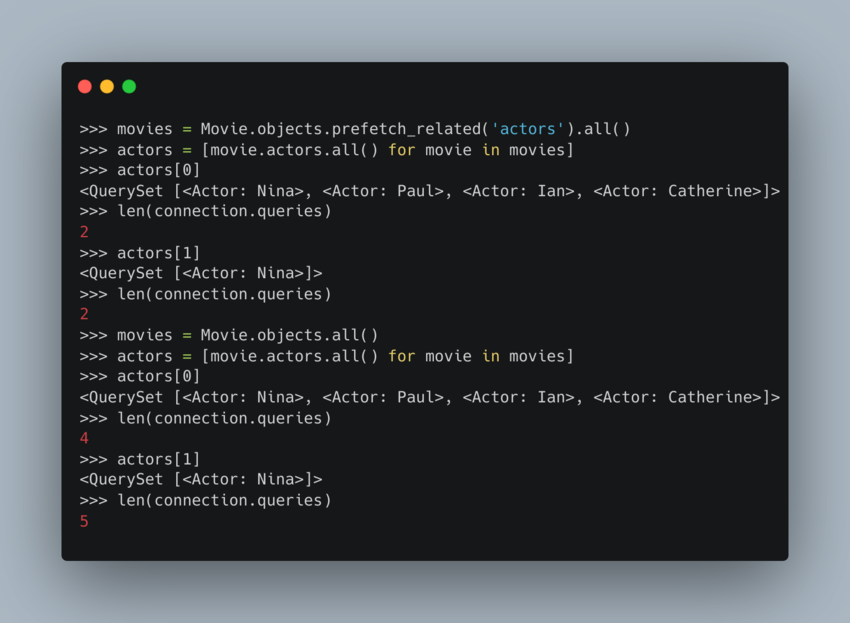
As you can see above, each iteration results in an additional query.
Now let's use prefetch to run the same query.
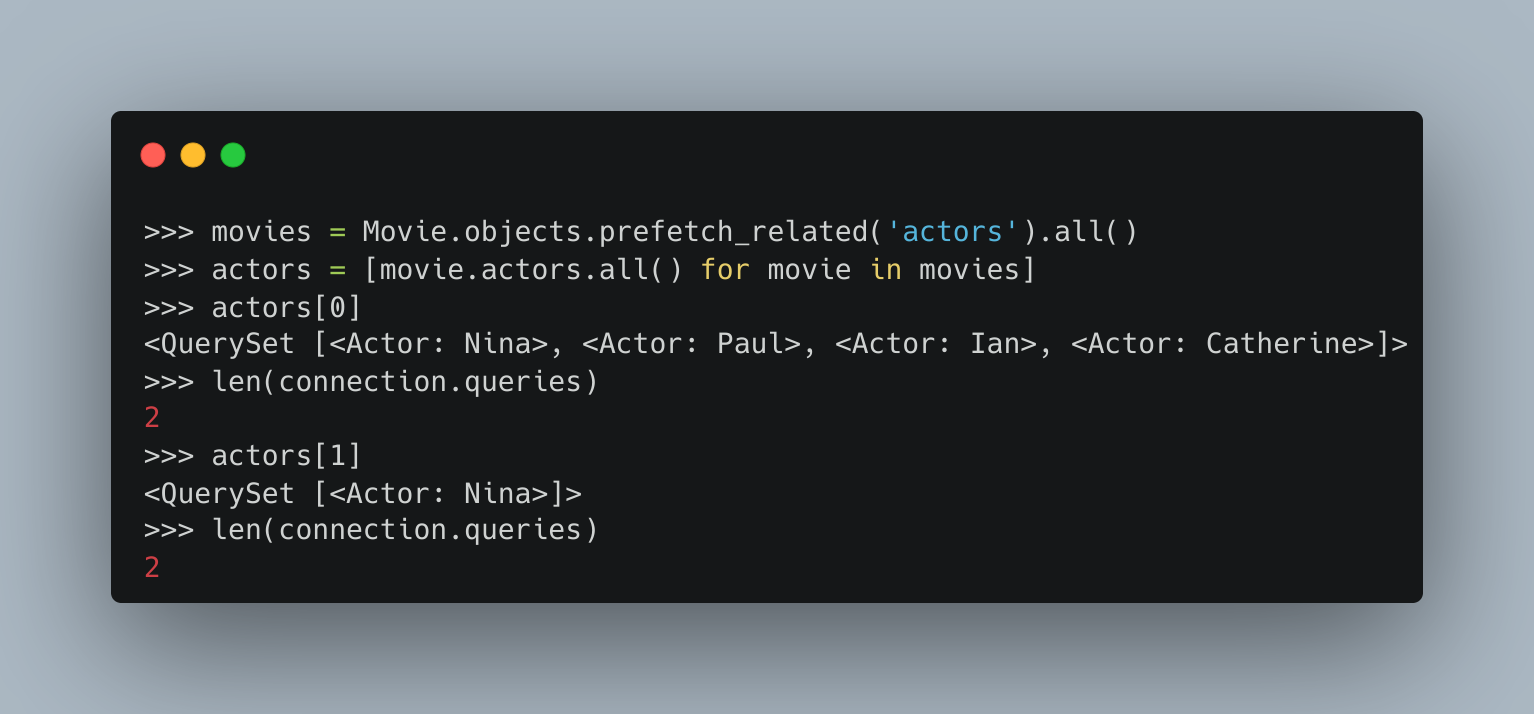
As you can see above, the query count is now 2, the first query fetches all the movies in the database, and the second and third request results in only a single query.
4. bulk method
Batching up is another code-performance way to retrieve queries.
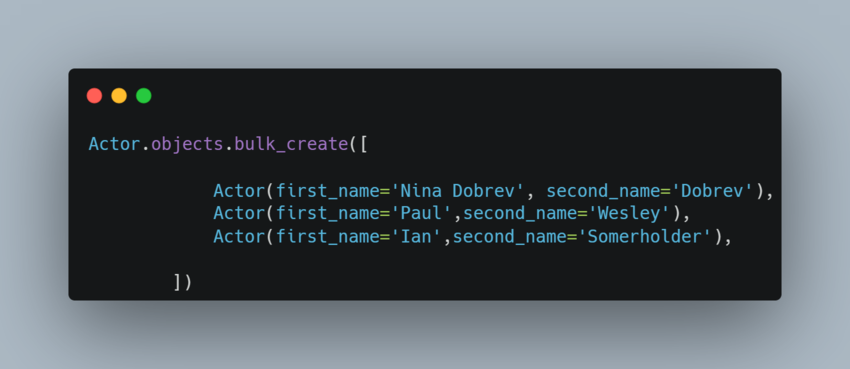
When you need to add multiple records to the database, the most efficient way is by creating all the objects at once. Luckily Django provides the bulk_create() method for that purpose. Rather than creating each instance at once and then returning it which overloads the database, bulk_create commits all the instances and does a single save query:
You can also do bulk_create and bulk_update(). For example, suppose you need to update a column in your database with a specific value; the most efficient way is using bulk_update as follows.
Model.objects.filter(name= 'name').update(name='someothername')5. RawSql
RawSQL is not recommended as Django provides top-notch query mechanisms that are guaranteed to,... every function you can think of.
The Django ORM can handle almost all the functionalities needed in your applications, but sometimes it can be necessary. Performing SQL queries on the database rather than Python leads to faster performance. RawSQL should be used as a last resort.
6. Foreign keys
Foreign keys can also be used to obtain data with no additional strains on the database. For example, if you want to get the owner of a tweet, the recommended and most efficient way is:
person = Person.objects.get(tweet__id =1)Monitoring Database Operations
It is good practice to monitor your database operations in production. It allows you to see queries run against your database and what errors are raised. You can do this by looking at your Postgres or Django logs from time to time. To make it easier, Sentry is a great tool for monitoring database operations.
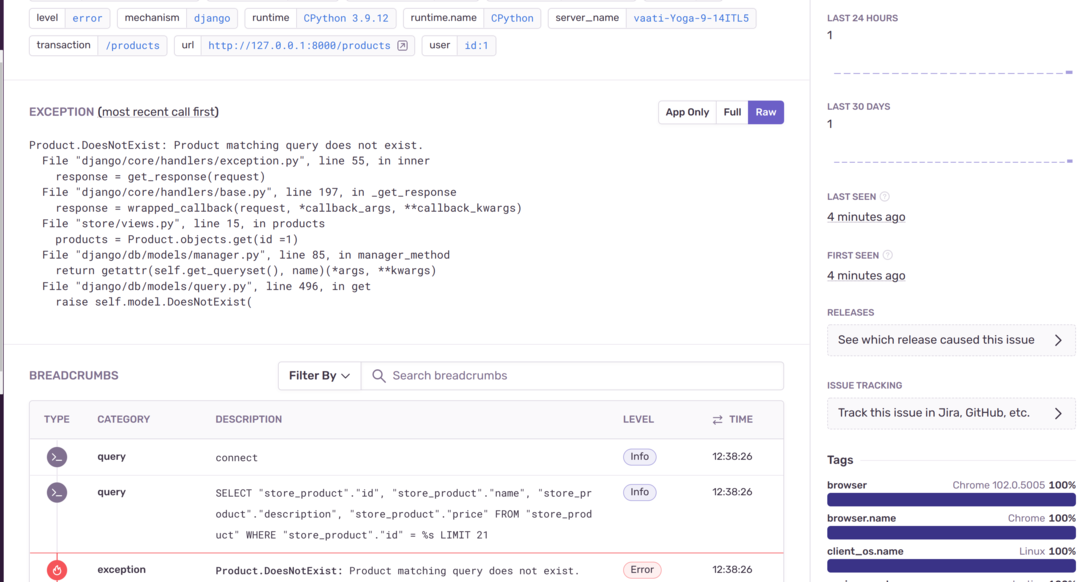
Sentry provides a dashboard for monitoring database operations in Django applications. In case of an error associated with the database, you can view it in real-time and solve it before your users even notice it happened.
Errors in production can be hard to detect since you don't have a debugger. Sentry solves this problem by allowing you to see every error in your database.
To get started, begin creating a Sentry account here. You will be able to choose which technology you are using. Choose Django and then click Create project.
Next, install Sentry via pip.
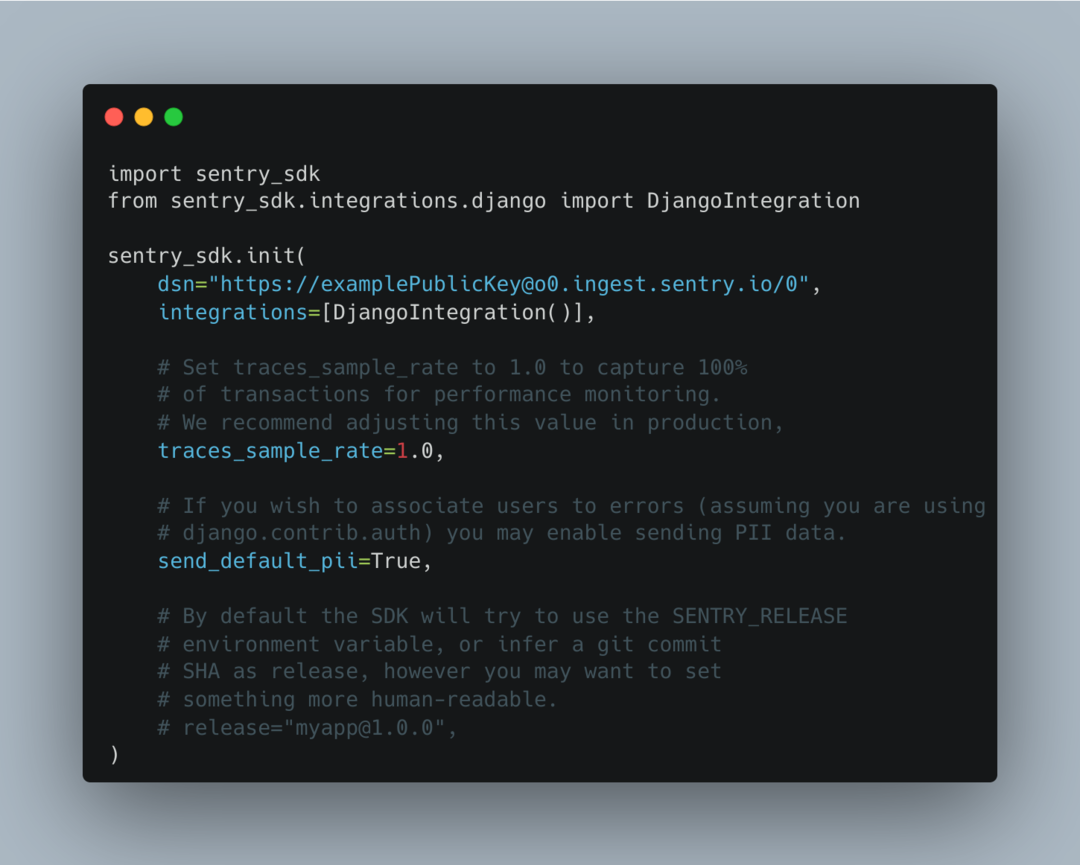
pip install --upgrade sentry-sdk The last step is to add the following code, which integrates your public key in the settings.py file in your Django application.
Sentry is now ready to monitor your application.
Let's create a database-related error in the database and see if Sentry can show us the cause. This is a sample error that I have in my local production caused by retrieving a product that doesn't exist in the database.
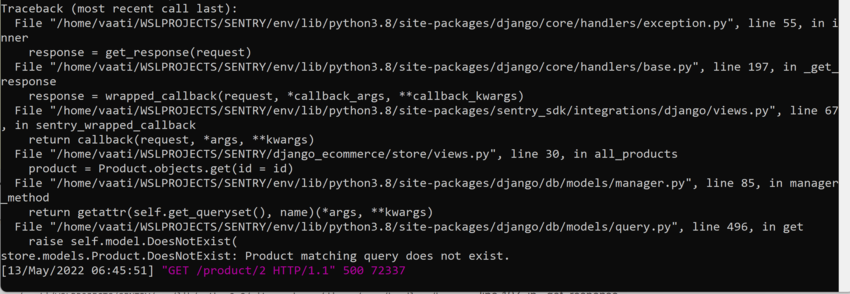
This error will also appear in your Sentry dashboard as shown below:
Django also provides tools like the Django Debug toolbar, which monitors your database, and you can see the request and response process in real-time. It also allows you to see how long it takes for each response to fetch data from the database.
The recommended way to install Django debug toolbar is using pip:
python -m pip install django-debug-toolbarOnce you install Django debug toolbar, it needs to be configured in the Django project.
Below is a screenshot showing the Django Debug toolbar in action:
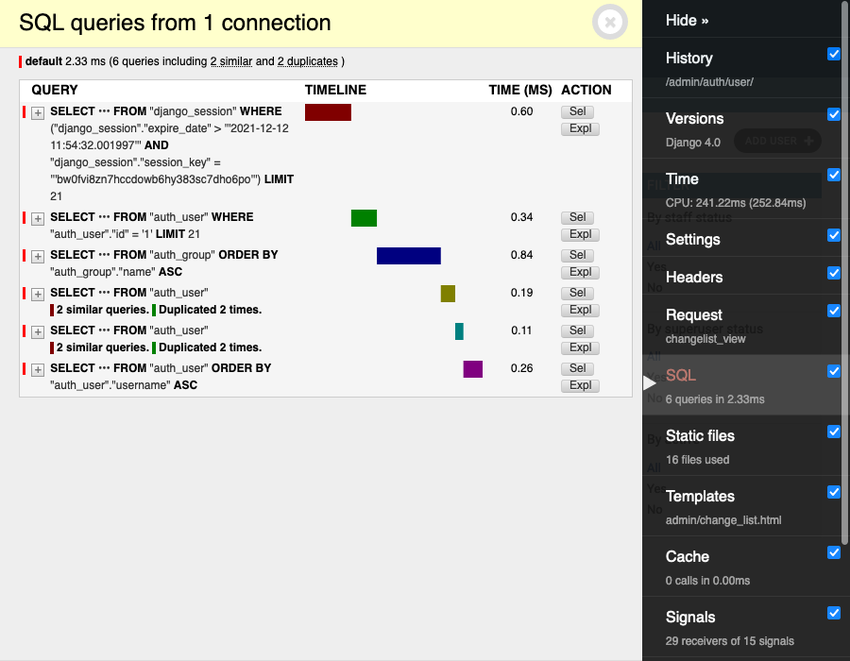
The drawback with using the Django debug toolbar is added overhead when rendering pages and thus is not suitable for construction. Sentry is preferred as it allows you to stay on top of bugs, gives detailed trace tracks about your database, and also allows you to troubleshoot issues.
Conclusion
This tutorial has covered ways in which Django can be used to improve the performance of your Django application and are also easy to implement. Give them a try, and stay tuned for parts 2-4 in this series.


