Code Mappings and Why They Matter
Code Mappings and Why They Matter


Code Mappings connect errors to the source code in a repository. And since errors can have paths that are different from the tree structure of the repository, Code Mappings determines the accurate path through a combination of a repository URL and a path transformation.
Sentry uses Code Mappings to serve issue context on the issue details page such as:
You can navigate to the source code in the repository directly from the Issue Details page
Issue Ownership and Code Owners
You can define path rules or use the code owners file from your repository to assign issues to teams
We can analyze who touched the line that triggered the error and suggest the person as the assignee
These features reduce the time to resolve production errors, by helping you quickly determine who owns the code in question.
Unfortunately, many developers weren’t able to use these features because of a cumbersome setup process for Code Mappings. Besides simplifying the process, we discovered that in some cases we could derive the Code Mappings on behalf of the user. Keep reading to learn how we enabled automatic Code Mappings, what it means for you, and what we have planned next.
Currently, automatic Code Mappings are only available for customers that have the GitHub integration installed (Team plans and higher) and for a limited number of languages.
Technical Challenges
Writing the code to automatically generate Code Mappings for a stack trace only took a few days, however, doing it at scale is what took the most time.
At Sentry we have tens of thousands of organizations and projects. And our customers have hundreds of repositories that their code can live in. Since we receive hundreds of thousands of unique issues an hour, the cost of running a processing job for every new issue would get pricey, fast. Thus, a more economical and scalable design was required.
Besides the ingestion considerations, we had to be strategic about how we use the GitHub APIs since we have to abide by a rate limit set by GitHub. Deriving Code Mappings is not the only feature that uses GitHub’s APIs, so we needed to be frugal and use caching properly. This is important since it would impact the behavior of other Sentry features (e.g. fetching commits from GitHub) until GitHub’s rate limit would be reset.
Deriving Code Mappings with GitHub’s APIs
Searching for the files mentioned in your stack traces requires two pieces of information:
The repository where the source code lives
The transformation required to match the file path
For instance, this stack trace frame sentry/shared_integrations/client/base.py is connected to this source file in Github: src/sentry/shared_integrations/client/base.py
In order to determine where the source code is found, we need a list of all the files and of all the repositories in the customer’s organization. To build this tree of files for every repository, we hit two GitHub APIs, the list organization repositories and get a tree API.
The first API (list organization repositories) fetches all repositories associated to an organization which we then use to fetch a tree for every repository. The second API call (get a tree) returns a repository tree representing all directories and files for a given repository. This API is very convenient since in one single call we get access to all the files for a repository.
From the tree response, we discard anything that is not a source code file, only include files that can raise an error.
Once we have the trees for all the repositories, we pick an issue for a project that has a stack trace and process it. We look for every frame file path to find unique matches across all the repositories, and search for the exact path at any depth within a repository (e.g. src/foo/bar.py and project/src/foo/bar.py would match sentry/foo/bar.py).
We could have used Github’s search API, however, it has a rate limit of only 25 requests an hour.
How we used Sentry for Sentry
Generally, before we go live with a new feature, we do some dogfooding to make sure things work as expected.
In the case of derived Code Mappings, we used the Performance and Dashboard products to build the analytics for the project.
There’s an API that the Issue Details page hits to determine if there are any Code Mappings associated with a project. In this API, we added various tags to answer the following questions:
Did a derived Code Mapping match the stack trace?
Did the generated URL based on the Code Mapping match a source file in GitHub?
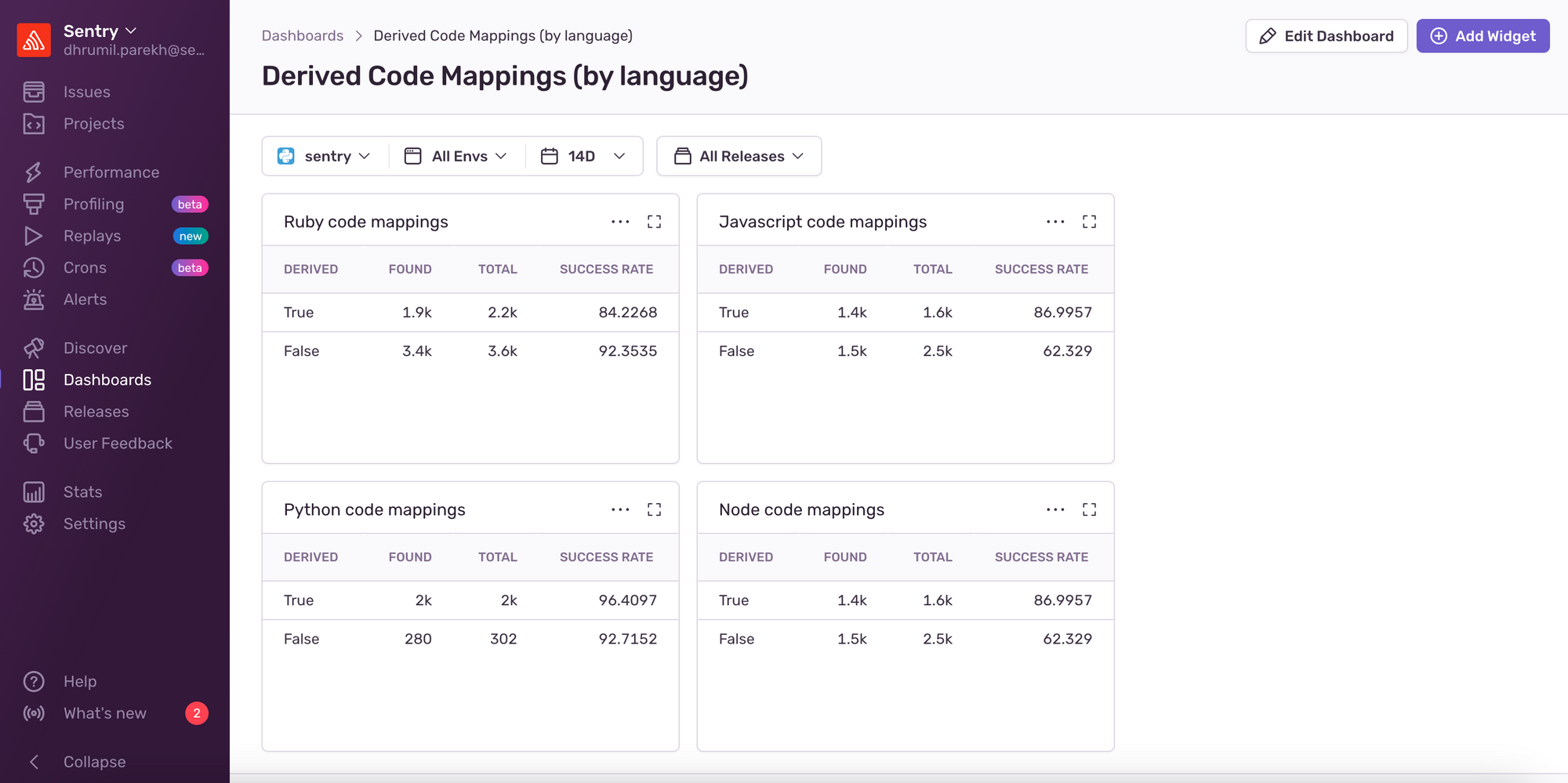
Tagging our API transactions led to determining which transactions used derived Code Mappings and if they found a file in GitHub. This allowed us to create a dashboard with widgets containing information about the success rate of the derived Code Mapping. For instance, JavaScript derived Code Mappings would have a success rate of over 85% while user-defined is about a 60% success rate.
What it Means and What’s Next?
Derived Code Mappings are currently only available to customers with the GitHub integration installed and for Python, JavaScript, Node and Ruby languages.
And remember, in order for derived Code Mappings to work, your organization needs to install the GitHub integration and grant access to all repositories. We cannot derive Code Mappings for repositories we do not have access to.
We’re looking to add many more languages and other source code integrations like GitLab and potentially BitBucket.


