Spring Boot Application Troubleshooting with Sentry


Maciej Walkowiak - Last Updated:

We previously wrote a quick guide to using Sentry with Spring Boot and Logback. Since then, we’ve continued improving the development experience, added several features for error monitoring and reporting, implemented comprehensive performance monitoring, added logs support for better debugging context, and introduced tracing capabilities for distributed system insights. The Sentry Java SDK has evolved significantly with dedicated integrations for Spring MVC, Spring WebFlux, and cloud-native environments. If you haven’t yet used Sentry in a Spring Boot application - nothing to worry about - you will find all the necessary steps below.
How to configure Sentry Spring Boot Starter
Sentry’s Java SDK is split into several modules, so that you pull only the dependencies you need. For Spring Boot users, the two most interesting ones are the sentry-spring-boot-starter and either the sentry-logback or sentry-log4j2 integration, depending on whether you use Logback or Log4j 2 as your logging framework of choice.
It’s important to always use the same versions for all Sentry dependencies. Mixing versions can cause unexpected issues, potentially discoverable only at runtime. To simplify version configuration, we’ve added something called a Bill Of Materials module (a concept you may be familiar with if you use Spring Cloud or Testcontainers) - sentry-bom - which, once included, ensures that all Sentry-related dependencies are in sync.
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.sentry</groupId>
<artifactId>sentry-bom</artifactId>
<version>8.17.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>io.sentry</groupId>
<artifactId>sentry-spring-boot-starter</artifactId>
</dependency>
<!-- to use Logback -->
<dependency>
<groupId>io.sentry</groupId>
<artifactId>sentry-logback</artifactId>
</dependency>
<!-- to use Log4j2 -->
<dependency>
<groupId>io.sentry</groupId>
<artifactId>sentry-log4j2</artifactId>
</dependency>
</dependencies>Once the dependencies are there, we can move on to configuration. The Sentry Spring Boot Starter uses Spring’s environment abstraction to retrieve configuration properties, which means it can be configured either through an application.properties file, Java system properties, environment variables, or a third-party service providing configuration to a Spring Boot application, like Vault or AWS Secrets Manager. Either way, if you’ve ever run a Spring Boot application in production, nothing will surprise you there.
While there are plenty of configuration options, you are only required to provide one, a sentry.dsn, which you can copy from your project settings in Sentry.
# application.properties
# replace dsn with a dsn specific for your Sentry project
sentry.dsn=https://b687180f91ef43e0908351beac84123a@o420886.ingest.sentry.io/6090909The Sentry SDK is meant to be invisible for your project, so as not to affect the performance or disturb your application logs. But, especially at the beginning when you want to ensure the integration works as expected, we advise you to turn on the Sentry SDK debug logs to check that the SDK is up and running and that events are successfully sent to the Sentry backend. Turn on the debug logs by setting the sentry.debug property to true.
# application.properties
sentry.debug=trueNow, every unhandled exception in a Spring MVC flow and every error log statement is converted into a Sentry event and sent to the Sentry backend.
You may have noticed that we haven’t touched the logging configuration at all - so how are error logs captured by Sentry? The Sentry Spring Boot Starter provides an auto-configuration for Logback - once it finds out that both logback and sentry-logback are in the classpath, it configures SentryAppender with some sane defaults - all error logs are converted to Sentry events, and all log statements with a level lower than error are converted into breadcrumbs, which it adds as metadata to an actual error - if one occurs.
While this configuration is convenient for many projects, if it doesn’t suit your needs, you can configure what is converted into an event and what is converted into breadcrumbs by changing the properties:
# application.properties
sentry.logging.minimum-event-level=info
sentry.logging.minimum-breadcrumb-level=debugWhen you need a more sophisticated appender configuration, you can also configure an appender in a logback.xml file manually, and auto-configuration will skip this step. You can also completely disable the SentryAppender configuration:
# application.properties
sentry.logging.enabled=falseHow to configure SentryOptions
SentryOptionsSentryOptions is a central object for configuring Sentry behaviour. In fact, when you set the sentry.dsn or sentry.debug property, it is set on SentryOptions.
There are plenty of configuration options. Today, we’ll focus only on those that are most important for a successful project integration:
The
sentry.environmentoptions specify in which environment your application runs. By default, we set it to production, so that we can easily distinguish between events coming from your other environments, like QA or staging. Make sure to give this property a meaningful value:
# application.properties
sentry.environment=stagingThe
sentry.releaseoption specifies the release version of your application. Once it’s there, you can see which release introduced an error or degraded performance. It can take any string as a value. For applications released with real version numbers, it’s a no-brainer, but many applications don’t use any kind of versioning and the actual version they use is a Git commit ID. Fortunately, you don’t need to set it manually.
To get a commit ID automatically assigned as a release, include this plugin:
<build>
<plugins>
<plugin>
<groupId>pl.project13.maven</groupId>
<artifactId>git-commit-id-plugin</artifactId>
</plugin>
</plugins>
</build>Gradle users can achieve the same result by using the gradle-git-properties plugin:
plugins {
id "com.gorylenko.gradle-git-properties" version "2.4.2"
}If configuring SentryOptions via simple values doesn’t fit your use case, you can also configure SentryOptions programmatically by registering a custom Sentry.OptionsConfiguration<SentryOptions> bean:
@Bean
Sentry.OptionsConfiguration<SentryOptions> customOptionsConfiguration() {
return options -> {
if (...) {
options.setSampleRate(..);
}
};
}How to filter exceptions in Sentry
Not every error is equal, so now you can easily filter out exceptions that you don’t want to be sent to Sentry:
sentry.ignored-exceptions-for-type=com.myapp.ServiceException,com.myapp.AppExceptionAgain, if your filtering logic is more complex, you can register a bean that has the BeforeSendCallback type. If this function returns null, an event will be excluded.
@Bean
SentryOptions.BeforeSendCallback beforeSendCallback() {
return (event, hint) -> {
if (...){
return null;
}
return event;
};
}Spring MVC integration
Sentry’s SDK shines especially with Spring MVC, where each event reported to Sentry is automatically decorated with all relevant contextual data about the HTTP request that triggered the event: the URL, request parameters, and headers - everything except the request body.
Request bodies can be attached to events only if a request has the application/json content type and requires the sentry.max-request-body-size property to be configured to one of the following values:
SMALL: If the body size is smaller than 1000 bytes, the body content is attached to the event.MEDIUM: If the body size is smaller than 10,000 bytes, the body content is attached to the event.ALWAYS: No matter what, the body content is attached to the event.
It is important to note that attaching a request body requires loading it to memory. Use this option wisely.
Since a request body can contain sensitive personal information, the Sentry SDK has to be configured with sentry.send-default-pii=true
Java SDK logs support
One of the major enhancements in recent versions of the Sentry Java SDK is its comprehensive logs support. Sentry can now capture and aggregate logs from your Spring Boot application, providing a centralized view of both errors and log data. This makes debugging much more efficient, as you can see the complete context surrounding an issue.
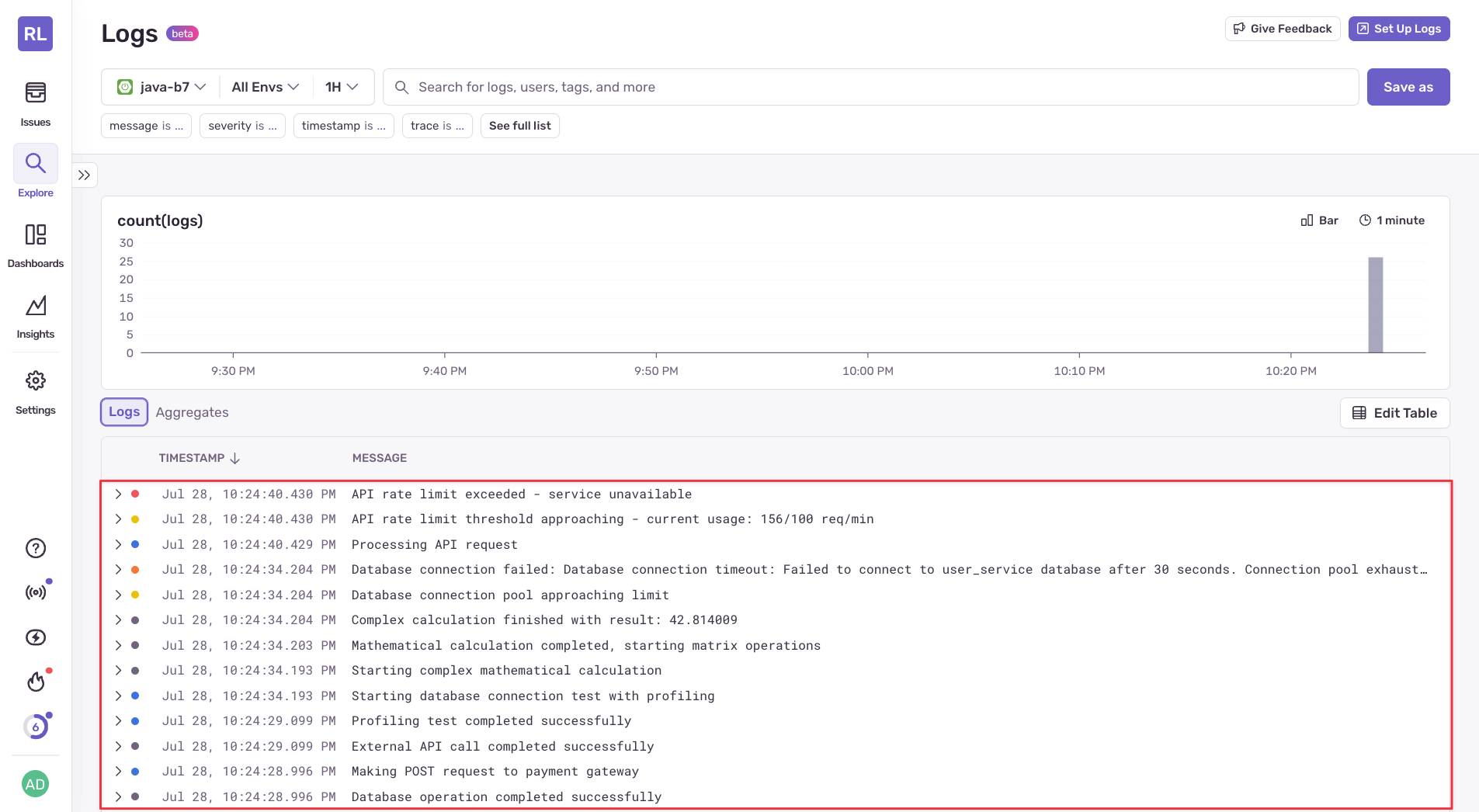
Spring Boot Logging
The logs feature works with the existing Logback and Log4j2 integrations. When enabled, Sentry captures logs at configurable levels and associates them with the current transaction or user session. This provides valuable context when investigating issues.
To configure logs capture, you can set the minimum log level that should be sent to Sentry:
# application.properties
# Capture logs at WARN level and above
sentry.logging.minimum-event-level=warn
# Capture breadcrumbs for INFO level and above
sentry.logging.minimum-breadcrumb-level=infoLogs are automatically enriched with contextual information like user data, tags, and transaction details, when available. This makes it easy to correlate log entries with specific user actions or performance issues.
Performance monitoring
In addition to a seamless error reporting experience, the Sentry Java SDK also offers application performance monitoring capabilities with the goal of discovering the causes and durations of delays in executing your application’s functions. Consult the Sentry Performance Monitoring docs to learn more about monitoring app performance.
To turn performance monitoring on, the Sentry SDK needs to know the percentage of potential traces that should be sent to Sentry - which likely depends on how much traffic your application takes. This can be configured using the simple sentry.traces-sample-rate property, which accepts values between 0.0 and 1.0, where 1.0 means 100% of traces will be sent to Sentry.
# application.properties
sentry.traces-sample-rate=1.0If the sample rate is more dynamic, for example if it depends on the URL, you can also register a bean that has the TracesSamplerCallback type to execute the sample logic for each incoming request:
@Bean
SentryOptions.TracesSamplerCallback tracesSamplerCallback() {
return context -> {
CustomSamplingContext customSamplingContext = context.getCustomSamplingContext();
if (customSamplingContext != null) {
HttpServletRequest request = (HttpServletRequest) customSamplingContext.get("request");
// return a number between 0 and 1 or null (to fallback to configured value)
} else {
// return a number between 0 and 1 or null (to fallback to configured value)
}
};
}Sentry ships seamless integration with Spring MVC out of the box. Each incoming HTTP request is turned into a transaction, and transactions can be further broken down into spans. Each span identifies the time needed to execute a certain part of the request execution, such as requests to external systems, executing database queries, or just calling beans methods.
RestTemplate instrumentation
RestTemplate instrumentationEach RestTemplate bean, created through a RestTemplateBuilder is automatically instrumented to create a span for each outgoing HTTP request.
@Bean
RestTemplate restTemplate(RestTemplateBuilder builder) {
return builder.build();
}Spans contain additional metadata, like request and response size. Interceptor requests get an extra sentry-trace header, enabling downstream services integrated with the Sentry SDK to continue a trace.
JDBC instrumentation
Often, the majority of the time needed to execute a request is spent waiting for a database server to execute a query. With the sentry-jdbc module in place, each query is turned into a span, so you can easily identify which queries need tuning.
Under the hood, sentry-jdbc uses P6Spy, which is a mature framework for intercepting JDBC activity. Take the following steps to enable JDBC tracing:
Add a dependency to the
sentry-jdbcmodule:
<dependency>
<groupId>io.sentry</groupId>
<artifactId>sentry-jdbc</artifactId>
</dependency>Include the
p6spyprefix in the JDBC URL:
spring.datasource.url: jdbc:p6spy:postgresql://localhost:5432/dbChange the database driver:
spring.datasource.driver-class-name: com.p6spy.engine.spy.P6SpyDriverDisable P6Spy log file generation by creating a file in src/main/resources/spy.properties with the following content:
modulelist=com.p6spy.engine.spy.P6SpyFactoryBean instrumentation
Every Spring bean method execution can be turned into a transaction or a span. To enable this feature, you must include the spring-boot-starter-aop in your application:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>Creating spans from method executions is as simple as annotating a bean method with @SentrySpan:
@Component
class PersonService {
@SentrySpan
Person findById(Long id) {
...
}
}Keep in mind that spans can be created only if they run within a transaction - which is provided for Spring MVC requests by default in the sentry-spring-boot-starter. But what about non-Spring-MVC use cases, like scheduled jobs or handling messages from message brokers? Well, it depends.
Similar to @SentrySpan, each method can be annotated with @SentryTransaction to mark the execution of the method as a transaction that can be broken down into spans. This works flawlessly for scheduled jobs or messaging, where message processing is not considered a continuation of an ongoing transaction started in another service. If a transaction is meant to continue a trace, however, we need to write some code.
As an example, we’ll use the Spring AMQP integration with RabbitMQ, but the principles stay the same for every messaging system capable of passing message headers.
To continue a trace, the message has to have a Sentry trace header. When sending a message, we can obtain the current trace header by calling Sentry.traceHeaders():
Message message = MessageBuilder
.withBody(rating.getBytes(StandardCharsets.UTF_8))
.setHeader(SentryTraceHeader.SENTRY_TRACE_HEADER, Sentry.traceHeaders().getValue())
.build();
rabbitTemplate.send("score-updates", message);On the listener side, we must retrieve the value of this header and start the transaction manually. We also need to consider that the header may have an invalid value - in such a case, the InvalidSentryTraceHeaderException is thrown, and we must decide to start a completely new transaction or to no longer start a transaction at all. In the following example, if the header has an invalid value, we will start a new transaction.
@RabbitListener(queues = "queueName")
void handleMessage(String payload, @Header(SentryTraceHeader.SENTRY_TRACE_HEADER) String sentryTrace) {
ITransaction transaction;
try {
// continue existing transaction from given sentry trace header
transaction = Sentry.startTransaction(
TransactionContext.fromSentryTrace("transactionName", "operation", new SentryTraceHeader(sentryTrace)), true);
} catch (InvalidSentryTraceHeaderException e) {
// start new transaction if sentry trace header is invalid
transaction = Sentry.startTransaction("transactionName", "operation", true);
}
...
}Once the transaction has started, we need to make sure that it always finishes, no matter whether the execution ended with an exception or finished successfully:
ITransaction transaction = // ...
try {
// ...
transaction.setStatus(SpanStatus.OK);
} catch (Throwable e) {
transaction.setThrowable(e);
transaction.setStatus(SpanStatus.INTERNAL_ERROR);
throw e;
} finally {
transaction.finish();
}The above block contains boilerplate code that you likely don’t want to have in your listener methods. Let’s refactor it into a reusable helper class:
class SentryTransactionHelper {
static void runInTransaction(String sentryTrace, String transactionName, String operation, Consumer<ITransaction> runnable) {
ITransaction transaction = startTransaction(sentryTrace, transactionName, operation);
try {
runnable.accept(transaction);
transaction.setStatus(SpanStatus.OK);
} catch (Throwable e) {
transaction.setThrowable(e);
transaction.setStatus(SpanStatus.INTERNAL_ERROR);
throw e;
} finally {
transaction.finish();
}
}
private ITransaction startTransaction(String sentryTrace, String transactionName, String operation) {
try {
// continue existing transaction from given sentry trace header
return Sentry.startTransaction(
TransactionContext.fromSentryTrace(transactionName, operation, new SentryTraceHeader(sentryTrace)), true);
} catch (InvalidSentryTraceHeaderException e) {
// start new transaction if sentry trace header is invalid
return Sentry.startTransaction(transactionName, operation, true);
}
}
}Now the actual listener code that should be wrapped in the transaction looks very clean and readable:
@RabbitListener(queues = "queueName")
void handleMessage(String payload, @Header(SentryTraceHeader.SENTRY_TRACE_HEADER) String sentryTrace) {
SentryTransactionHelper.runInTransaction(sentryTrace, "transactionName", "amqp", transaction -> {
// metadata can be added to transaction
transaction.setData("payload", payload);
// code that handles the message
});
}Distributed tracing
Sentry uses distributed tracing to track your software performance, measuring metrics like throughput and latency, and displaying the impact of errors across multiple systems. Sentry captures distributed traces that consist of transactions and spans, which measure individual services and individual operations within those services.
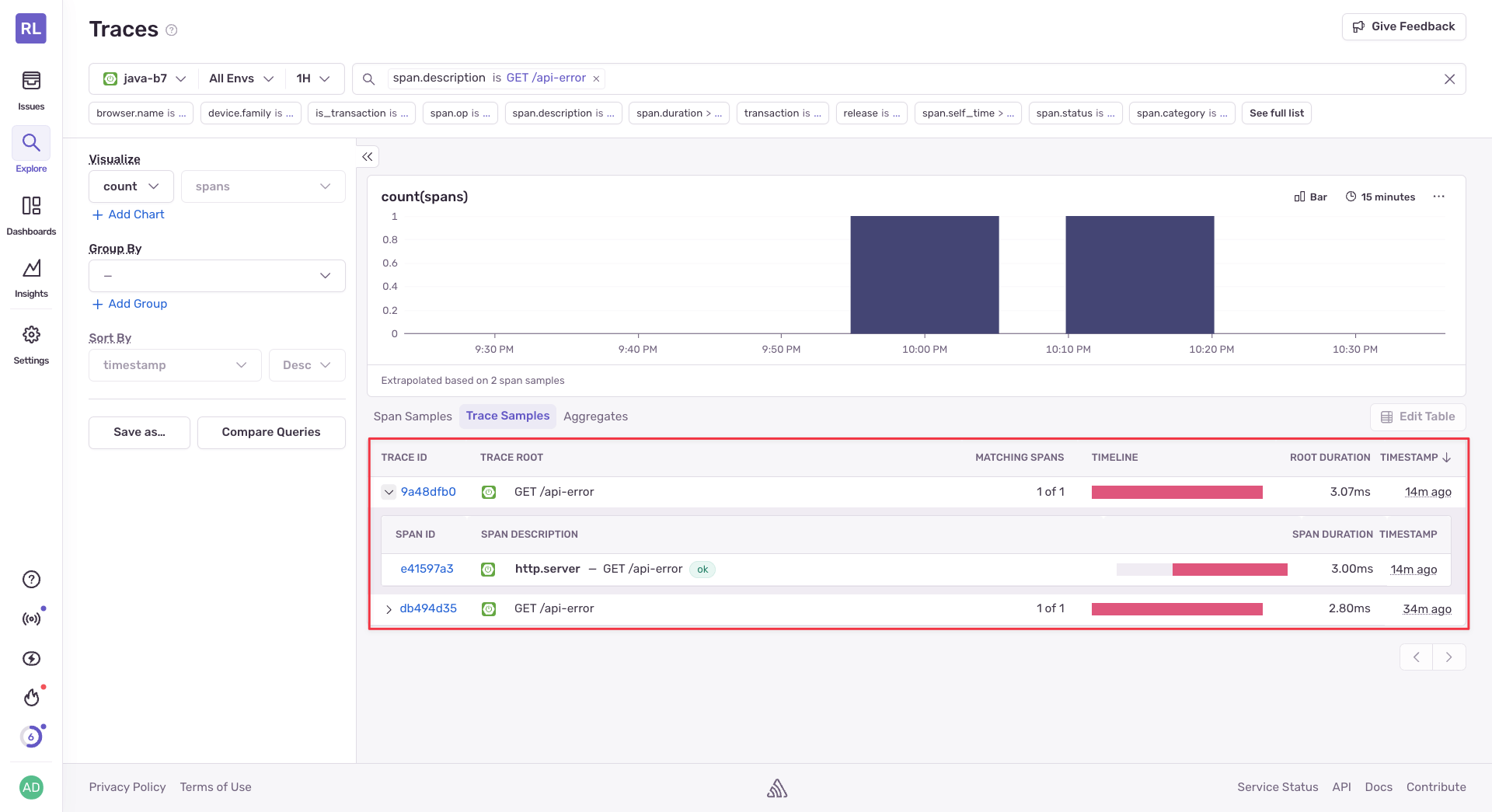
Spring Boot Tracing
To enable tracing in your Spring Boot application, you need to configure the sample rate for transactions:
# application.properties
# Set traces_sample_rate to 1.0 to capture 100%
# of transactions for tracing.
# We recommend adjusting this value in production.
sentry.traces-sample-rate=1.0You can also control the sample rate based on the transaction context by providing a custom traces sampler:
@Component
class CustomTracesSamplerCallback implements SentryOptions.TracesSamplerCallback {
@Override
public Double sample(SamplingContext context) {
CustomSamplingContext customSamplingContext = context.getCustomSamplingContext();
if (customSamplingContext != null) {
HttpServletRequest request = (HttpServletRequest) customSamplingContext.get("request");
// return a number between 0 and 1 or null (to fallback to configured value)
return 0.5; // Sample 50% of transactions
} else {
// return a number between 0 and 1 or null (to fallback to configured value)
return 0.1; // Sample 10% of transactions
}
}
}Without sampling, automatically captured transactions can add up quickly. The Spring Boot integration, for example, sends a transaction for every request made to the server.
Tracing works seamlessly with existing annotations:
// Tracing works automatically with existing annotations
@Component
class OrderService {
@SentrySpan
public Order processOrder(OrderRequest request) {
// This method execution will be traced when sampling triggers
return orderRepository.save(buildOrder(request));
}
}There's way more to the Java SDK
Along with the Sentry Spring Boot Starter, the Java SDK contains integrations with Log4j2, JUL, traditional non-Spring servlet applications, OpenFeign, the Apollo GraphQL client, and the GraphQL Java library (the foundation for Spring GraphQL and Netflix DGS). Recent versions also include enhanced support for reactive frameworks, like Spring WebFlux, and improved integrations with cloud-native environments.
Head over to the Sentry Java SDK docs to learn more about these integrations and discover advanced configuration options for enterprise deployments.