Shipping Sentry 9
Shipping Sentry 9



One month after launch Sentry 9 may feel as though it descended from heaven, but it didn’t simply fall out of the sky. It’s a release that was long in the making, touched by virtually every member of our application engineering team. We made 1979 commits to our getsentry/sentry repo alone, with 2698 files changed, 458546 insertions, and 166290 deletions.
Our focus for this launch was on cutting through the noise to ensure you see errors that are more relevant and actionable than in the past. There are at least three potential buzzwords in that last sentence, so how did we set out to accomplish these goals in a genuinely valuable way?
It all starts with the changes we made to Teams.
Teams
With a special thanks to Jess and Max.
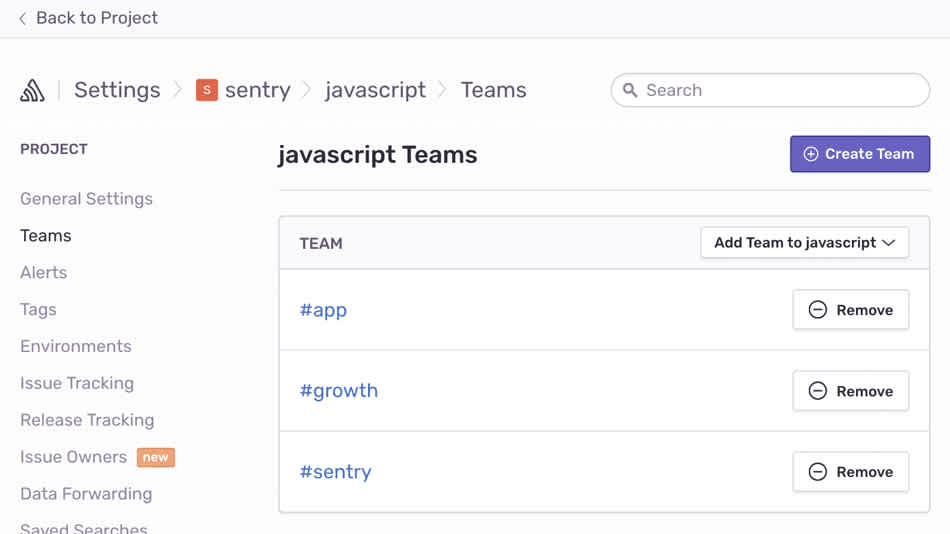
Very little of what we did in this release would have been possible without the update to Teams. It added the option to assign multiple teams to an individual project, as well as assign those teams as owners of individual issues or entire sections of your codebase, and ping entire teams in comments.
It was a tricky update, mostly involving schema changes and the migration of tons of data. But those schema changes weren’t necessarily the tricky part.
What was?
We previously had a database constraint that ensured that Projects can only have one Team. We removed that constraint six months ago to prepare for all the upcoming team-based feature changes, but did so in a way that was invisible to users. We need to ensure we never allowed an organization to associate two teams with the same project, which would have been a weird experience without the accompanying UI changes.
This touched so many lines of code that we really just didn’t want to miss anything and leave the wrong functionality in place somewhere. We needed to carefully replace the table managing the one team to many projects hierarchy with a many teams to many projects table. That meant adding the new table, dual writing to both the new and old tables, backfilling the new table with data from the old, and then finally cutting the reads over (see our PR for that last part).
Moving from a one-to-many hierarchy to a many-to-many hierarchy meant we had to account for situations that weren’t previously possible, like now that a project could have many teams associated with it, it was also possible for it to have no teams associated with it (which would make the project useless).
With Team functionality in place, we could make our next feature much more valuable.
Issue Owners
With a special thanks to Matt, Lauryn, and Max.
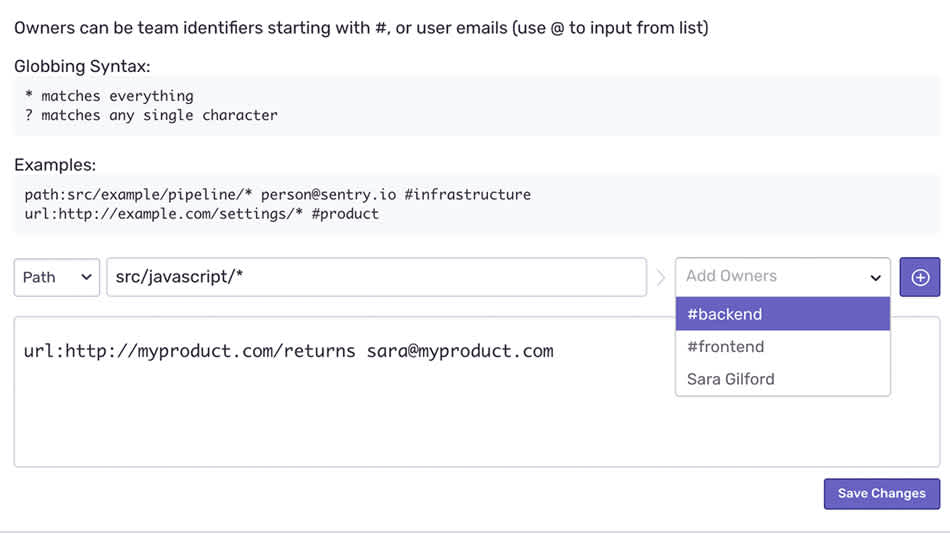
Issue Owners allows you to assign different parts of the codebase connected to a Project to different teams (something that would not have been possible minus the Team(s) work noted above), individual engineers, or a mix of both. Then only those teams and engineers designated as owners see notification about the bugs related to what they own.
We truly began to understand the need for this feature as our own engineering team grew. If every developer working on a large Project sees all the same email notifications, then they become more likely to start tuning those emails out and less likely to notice the issues that need their attention.
What were the keys to making this a useful feature?
Assigning ownership to various parts of a codebase in a way that would be both functional and useful. Code path was obvious, so we went with that and threw in URL on top of it. We'll likely expand on this as we go.
Ensuring no Issues could end up lost in the ether just because there was no person or team assigned to the part of the codebase where the error occurred. This was solved by including a setting that continues to send an email to all members of a project if more specific ownership cannot be determined. (It can be turned off, but it defaults to on.)
Making changes to how our notification emails are triggered. Previously, emails went out to every single person working on a project, but now they needed to go out only to owners of an Issue.
Using the Issue Owners features also requires spending time adjusting settings, which was one reason we decided to tackle a:
Settings Pages Redesign
With a special thanks to Chris, Billy, Chrissy, and Lyn.
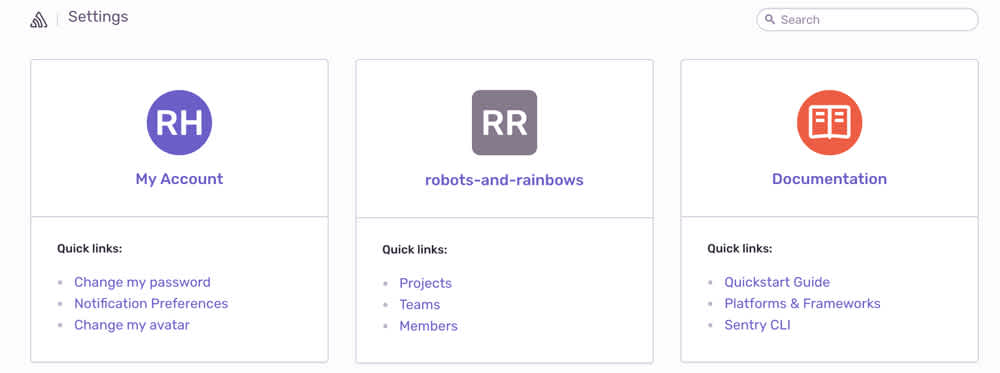
Just going by sheer number, our settings pages have by far the biggest footprint in Sentry. How many pages exactly? 64. Settings are also usually the first part of Sentry that users in encounter. And it’s important to us that we make a good first impression.
So we thought, “Hey! Wouldn’t it be cool if Settings were more organized and maybe searchable?”
Indeed. That would be cool. Which is why we overhauled them to be faster, more consistent, and easier to navigate:
Our old settings were slow, static html pages that required a full refresh and felt really sluggish compared to the rest of the app. In Sentry 9 we converted them to React, which greatly improved performance and page rendering speed.
We implemented a new breadcrumb navigation that helps you find your way around, while also allowing you to jump to the same settings page on a different project or organization, making it possible to adjust settings for multiple projects quickly.
We reduced page complexity by removing project and organization overlay / chrome.
We created a consistent UI that matches the rest of the application.
Eventually the entire application team touched Settings in some way, which makes sense considering most Sentry functionality is in some way connected to Settings. Including the last major feature of Sentry 9:
Environments
With a special thanks to Ted and Lyn.
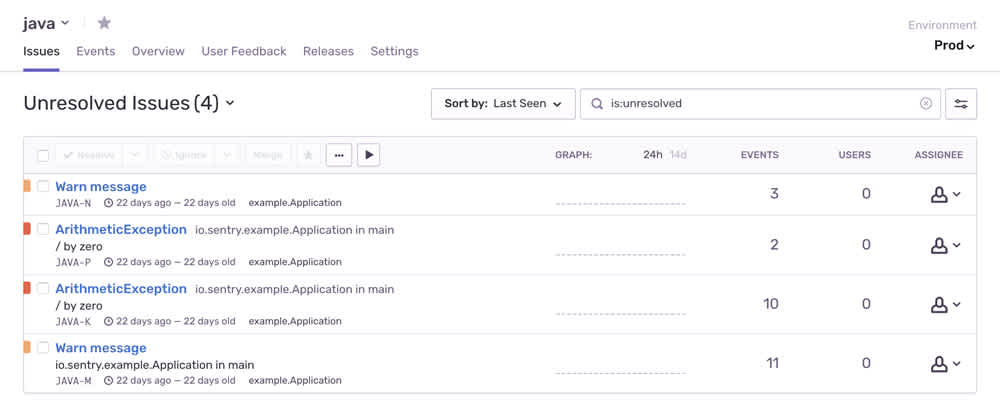
The value of the Environments feature is straightforward. There's an implicit prioritization attached to a deployment environment. Something that happens in QA or Staging is probably not as important as something that happens in Production. At the very least, remediating the problem is likely to be more urgent when it’s an issue directly impacting customers.
As a feature, Environments seems simple. You're presented a drop-down menu from where you can drill-down to errors based on the development environment where they occurred. Everything is not always as simple as it seems:
Much like with teams, we had to take into account the sheer number of pages in Sentry impacted by toggling Environments. Pages like Releases and User Feedback needed to be modified.
On the infrastructure side of things, Environments represents a dramatic increase in the number of data points that we have to store for basically every event we receive. Since we pre-compute time-series data (and all our aggregated data), we now have to store multiple computed values for each specific environment, and for all environments cumulatively. This is an order of magnitude higher than what we were previously computing. It was also necessary to update every API endpoint that derived data from event ingestion.
Environments are currently available for both new organizations and early adopters. Do you have an older account, but aren’t an early adopter? Don’t worry, you can become one by flipping a switch in our much improved Settings for your Organization. It’s the third option under General Settings.
If you'd like to take an even closer look at how we put the Sentry 9 features together, just visit Sentry on GitHub. We are open source, after all.
Also, bonus tip: Want to quickly jump to a particular setting, project, or organization? Give our new command palette (⌘+k) a try!


