Missing indexes are slowing down your database - here's how to find and fix them with Sentry
Missing indexes are slowing down your database - here's how to find and fix them with Sentry


Slow database queries drag down performance for both developers and users. They waste resources, slow down testing, and frustrate customers with laggy experiences. But often, there’s a surprisingly simple fix: indexing.
Here’s how indexing works and when to use it, regardless of your schema.
If you know what an index is & how to use it, and are more interested in learning how to monitor and debug slow queries, jump to our example here.
What is an index?
So, what the heck is an index anyway? Think of an index as your database’s GPS. Without it, your database searches takes the scenic route, checking every single row like it’s a lost tourist. With it, your user’s transactions go straight to the data it needs.
Technically, an index is a smaller structure that maps column values to rows, making lookups lightning-fast.
Let’s take an example; say you’re querying emails from a users table or collection. For SQL databases, an example index for email column lookups on the users table might look like this:
CREATE INDEX idx_users_email ON users(email);
MongoDB and other NoSQL document-based databases index in a similar way. In this case, we’re looking up the email value in the users collection:
db.users.createIndex({ email: 1 });
Indexes aren’t magic, but they feel like algorithmic sorcery (think binary search trees or hash maps). When a query involves an indexed field, the database skips the full table scan and instead checks the index for matches. This can be a game-changer for building fast queries.
Indexes are powerful, but they aren’t free. Abusing indexing can lead to slower write operations (since every write requires updating the index), increased storage (since indexes need space too), and diminishing performance returns (since you clog up the optimizer with indexes to choose from).
Let’s break down when and where indexing is worth it.
When to index in SQL and NoSQL
Not every column or field needs an index. To avoid overloading your DB, focus on the areas where indexes make the most impact. Here’s a quick guide for how to decide:
Common Indexes in SQL
Primary Keys: Every table has one primary key, a unique identifier for each row (e.g.
id). Most databases automatically index primary keys, making it the fastest way to look up rows.Foreign Keys: These connect tables in relationships, like linking
ordersto theircustomers. Indexing these fields is essential for fastJOINs.Filtered columns: Filters like
WHERE,ORDER BY, orGROUP BYare prime candidates. For example,SELECT * FROM products WHERE category = 'Electronics';can be dramatically sped up by creating an index:CREATE INDEX idx_products_category ON products(category);. This is also applicable to multicolumn, compound indexes likeproducts(category, warehouse)
Common Indexes in MongoDB
Frequently Queried Fields: if a field is used often in
find()filters e.g.find({ status: "active" }), indexing it allows MongoDB to locate the matching docs quickly.Nested Fields: in MongoDB, data is often stored as nested objects. Frequently querying these nested fields e.g.
"customer.name", indexing them ensures fast lookups. A simple example:db.orders.createIndex({ "customer.name": 1 })Compound Fields: similar to compound indexes in SQL, indexes involving multiple conditions can store combined key values and optimize common MongoDB queries:
db.orders.createIndex{( customerrId: 1, orderDate: -1 })
Tip: Avoid indexing fields with low selectivity (e.g., status with repeated values like active/inactive), those rarely queried, or highly volatile data like last_seen timestamps in write-heavy tables. Over-indexing (too many indexes on a single table) or indexing large, infrequently filtered fields (e.g., text blobs) can degrade performance and waste resources.
Finding and fixing index-worthy queries in your application
1: Start with Performance Monitoring
Before diving into query specifics, focus on high-impact areas of your app. Database performance monitoring tools like Sentry provide an overview of your app’s slowest database operations. Look for:
High-impact queries: Find queries that consume the most time or appear frequently in critical user flows.
Patterns across transactions: Identify common bottlenecks in high-traffic endpoints or recurring transactions
Context: See how slow queries affect the performance of your stack (e.g. are they delaying API responses or blocking frontend rendering?)
This approach ensures you’re prioritizing fixes that will meaningfully improve user experience, not just shaving milliseconds off obscure operations.
2: Diagnose with Database Tools
Once you’ve spotted problematic queries, use your database’s built-in diagnostic tools to dig deeper:
SQL: Use EXPLAIN
EXPLAIN SELECT * FROM products WHERE category = 'Electronics';
This command returns the “query execution plan”, including a performance score and some other useful info, such as whether or not it’s using an index or going through each row. You will see an example of this in our example down below.
If you see a Seq Scan , it indicates an unindexed “full table scan” and is likely a good candidate to add an index.
NoSQL: Use .explain()
db.products.find({ category: "Electronics" }).explain("executionStats");
In databases like MongoDB, .explain() provides similar insights but has different terms.
If you see a COLLSCAN, it’s likely time to set up an index.
3: Apply and Test Indexes
SQL:
Add an index to the column you’ve identified. Be as specific as possible to avoid over-indexing:
CREATE INDEX idx_products_category ON products(category);then...
RunEXPLAINagain to ensure the query now uses the index (Index ScanorBitmap Heap Scan), with reduced cost.
EXPLAIN SELECT * FROM products WHERE category = 'Electronics'; -- Outputs the updated query execution plan, confirming if the new index is being used and reducing the query cost.
NoSQL:
Add an index using the .createIndex command, e.g.
db.products.createIndex({ category: 1 })then...
Check.explain()for a switch fromCOLLSCANtoIXSCAN.
db.products.find({ category: "Electronics" }).explain("executionStats"); // Verifies that the query now uses an index (IXSCAN) instead of scanning the entire collection (COLLSCAN).
By focusing on high-impact queries and testing your fixes, you can quickly improve database performance. Performance monitoring ensures you’re solving the right problems, and indexing can be a key part of the solution.
Phew. That’s a lot off my chest.
Now that we know how indexes work to speed up your applications, how to identify quick wins, how to create indexes, and how to verify the improvements, let’s see how you can use Sentry to streamline the process of finding & debugging missing indexes with a real-world example.
Finding and fixing a missing index in a habit tracking app with Sentry
Let’s take a look at a recent example from Benjamin Coe, a product lead on Sentry's Insights team. He had spun up a habit tracker app for a demo, but it was running noticeably slow whenever users interacted with the homepage.
1: Finding the culprit query in our haystack
The first thing we needed to do was spin up Sentry so we could monitor for the slow query. We’re using a Postgres DB with JavaScript, so we didn’t need to do anything special - things like MongoDB, MySQL 1/2, GraphQL etc. are automatically instrumented. All we had to do is make sure Tracing is correctly set up in our SDK config. Now, let’s get into it.
After a few minutes, user transactions started flowing in, and we pulled up the Backend Insights tab to see our most time-consuming queries from across the full stack. There was one query sticking out like a sore thumb:
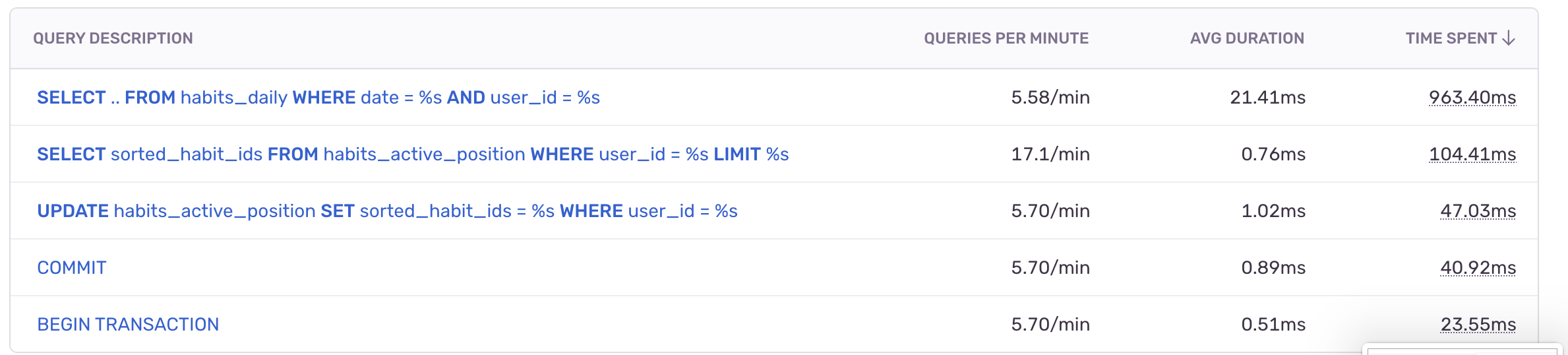
The top SELECT query is taking ~20x longer than our next slowest query, leading to ~10x total time spent processing than any other query. Clicking in showed us the full query:
SELECT "name", "status", "habit_id", "status", "date", "days" FROM "habits_daily" WHERE date = $1 AND user_id = $2
This should be a pretty simple fetch - we’re just getting all the habits for a specific date and a specific user. Why is it taking so long?
2: Run an EXPLAIN query to see if it’s correctly indexed
EXPLAIN query to see if it’s correctly indexedBy SSHing into our database server and running an EXPLAIN on the query, we were able to analyze the query's performance:
EXPLAIN select "name", "status", "habit_id", "status", "date", "days" from "habits_daily" where date = '2024-08-28' AND habits_daily.user_id = 'd0e1779f-dbf8-4276-a65f-38c08d331fe4'; Gather (cost=1000.00..5535.84 rows=1 width=143) Workers Planned: 2 -> **Parallel Seq Scan on habits_daily** (cost=0.00..4535.74 rows=1 width=143) Filter: ((date = '2024-08-28'::date) AND (user_id = 'd0e1779f-dbf8-4276-a65f-38c08d331fe4'::uuid))
We could easily see this query was running a full, unindexed Parallel Seq Scan here, and intends to use two parallel workers to gather the data. All of this to fetch a 143-byte wide row. Adding an index should be a quick fix, so we gave it a shot.
Note: The attentive among you might notice that we had to add a specific date to the query here - Sentry uses variables in SQL to find insights, but EXPLAIN doesn’t work with variables ie. date = $1 AND habits_daily.user_is = $2 so we had to replace them with specifics. With Sentry, it’s easy to recreate these queries by going into a specific trace and copying that into your EXPLAIN command.
3: Add an Index to the culprit query
Indexing the dates in this table is super easy. We just pulled up our DB CLI and threw in the following commands:
CREATE INDEX habits_daily_date_idx ON habits_daily(date); SHOW INDEX FROM habits_daily; -- gives us the collation/cardinality to make sure it's correctly config'd
This created an index on the habits_daily table for the date column. Now, if we run the same EXPLAIN operation on the same query, we see:
Bitmap Heap Scan on habits_daily (cost=4.35..31.52 rows=1 width=143) Recheck Cond: (date = '2024-08-28'::date) Filter: (user_id = 'd0e1779f-dbf8-4276-a65f-38c08d331fe4'::uuid) -> Bitmap Index Scan on habits_daily_date_idx (cost=0.00..4.35 rows=7 width=0) Index Cond: (date = '2024-08-28'::date)
We can immediately see the impact here. Now, we’re clearly running a Bitmap Heap Scan when we’re querying this table. This fetches the row pointers directly from the index, instead of using parallel workers to read the entire table.
The estimated cost dropped from 4535.74 down to 4.35, about a 1000x cost improvement.
Note: user_id is the Primary Key on this table, it’s indexed by default. If it wasn’t, and we wanted to index this common operation, we’d create a composite index by using CREATE INDEX [...] ON habits_daily(user_id, date)
4: See the fix in action with Sentry
Let’s head back to Sentry’s Backend Insights tab to see if the fix is working for users in production.
Sure enough, there’s a ~20x increase in speed:
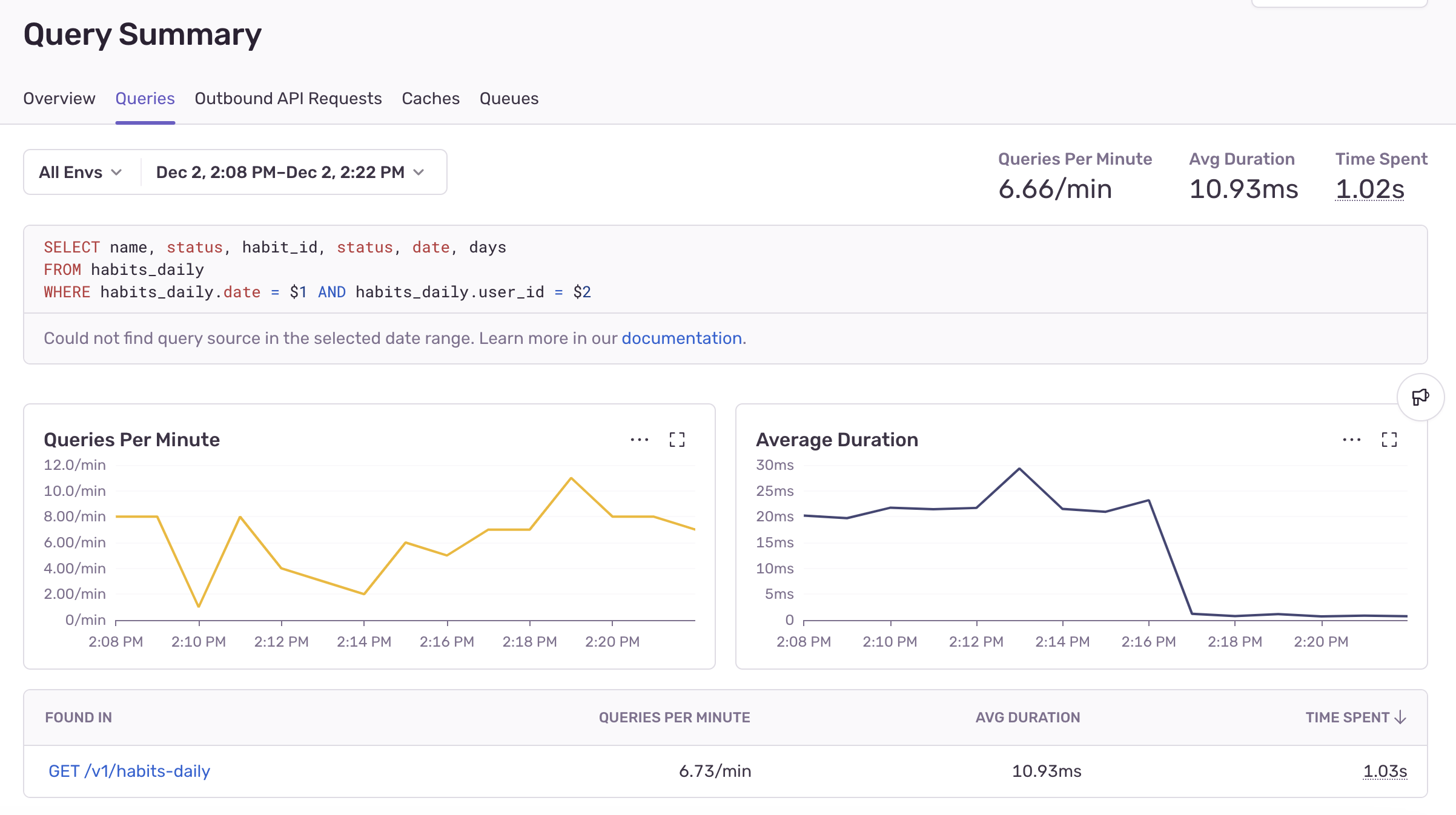
This whole process took maybe 15 minutes from identification to resolution & verification. Instead of digging into our database and testing every index on every table manually, we were able to instantly find the needle in our haystack, test for proper indexing, and verify the fix for real-world queries in production.
Find slow queries and make them lightning-fast with Sentry
TL;DR - Sentry’s Backend Insights identifies slow queries, shows where your backend lags, and provides the context needed to prioritize and tackle performance bottlenecks—whether it’s an unoptimized query, missing index, or inefficient transaction.
This is just one of the many ways you can use Sentry’s distributed tracing and insights to uncover performance bugs in your backend. In future posts, we’ll explore caches, queues, DB operations and more.
Start by instrumenting your app with Sentry’s Tracing, explore Backend Insights to identify pain points, and follow the steps to diagnose and fix slow queries. Don't have a Sentry account? Get started for free. Have questions? Ask us on Discord.